W przypadku gdy macie na dysku zainstalowane dwa systemy i jest to Linux oraz Windows może zdarzyć się, że któryś z nich trzeba przeinstalować. Nie ma problemu gdy jest to Linux, ale jeżeli musisz przeinstalować Windowsa to wtedy musisz się liczyć z tym, że stracisz dostęp do swojego linuxowego bootloadera, ponieważ Windows załaduje swój program bootujący.
Jeżeli chcesz odzyskać swojego Gruba musisz wykonać następujące czynności:
1. Odpalasz swoją ulubioną dystrybucję LiveCD.
2. Wchodzisz do terminala i jako root uruchamiasz program konfiguracyjny Grub:
sudo grub
3. W programie odnajdujesz dyski na których ustawione jest bootowanie:
find /boot/grub/stage1
4. Wynikiem będzie np. coś takiego: (hd0,6). Wydajesz następujące komendy:
root (hd0,6)
setup (hd0)
quit
5. Restartujesz komputer i cieszysz się z możliwości wyboru swojego ulubionego systemu.
poniedziałek, 29 grudnia 2008
sobota, 27 grudnia 2008
Błąd "Check your system clock" podczas instalowania pakietów na Linuxie
Czasami może zdarzyć się, że podczas instalowania nowego programu na ze źródeł wyświetli Ci się następujący błąd: "Check your system clock". Oznacza to, że masz nieustawiony zegar systemowy i być może również sprzętowy. Należy je ustawić. Wydajemy następujące komendy:
1. Ustawiamy zegar czasowy (aby zrobić to dokładnie należy wpisać czas z lekkim wyprzedzeniem, poczekać aż taki czas nadejdzie i wcisnąć enter):
date -s "30/12/2009 13:36:30"
2.Ustawiamy czas sprzętowy. Logujemy się jako root:
/sbin/hwclock -r
/sbin/hwclock --adjust
/sbin/hwclock --systohc
3. Restartujemy komputer i ponownie próbujemy zainstalować nie działające wcześniej pakiety.
1. Ustawiamy zegar czasowy (aby zrobić to dokładnie należy wpisać czas z lekkim wyprzedzeniem, poczekać aż taki czas nadejdzie i wcisnąć enter):
date -s "30/12/2009 13:36:30"
2.Ustawiamy czas sprzętowy. Logujemy się jako root:
/sbin/hwclock -r
/sbin/hwclock --adjust
/sbin/hwclock --systohc
3. Restartujemy komputer i ponownie próbujemy zainstalować nie działające wcześniej pakiety.
niedziela, 21 grudnia 2008
Pozycjonowanie stron za pomocą wyboru najbardziej popularnych słów kluczowych poprzez keyword tool
Dzisiaj trochę o pozycjonowaniu stron, a właściwie o jednej ciekawej metodzie pozycjonowania, mianowicie o doborze odpowiednich słów kluczowych dla Twojej strony. Wielu z was na pewno uważa, że w pozycjonowaniu najważniejszy jest jak najwyższy ranking pagerank, lub duża ilość linków prowadzących do Twojej strony. To oczywiście jest prawdą ale nie do końca. Nawet jeżeli Twoja strona ma wysoki pagerank to co to zmieni jeżeli słowa kluczowe Twojej strony, które są tak wartościowe w wyszukiwarkach, są wpisywane przez internautów 200-300 razy w miesiącu? Nawet jeżeli każda tak wpisana fraza zaprowadzi internautów do Twojej strony to masz 300 unikalnych wejść w miesiącu, co nie jest dużo. Oczywiście może się zdarzyć, że prowadzisz stronę o jakimś unikalnym temacie, o czymś do czego ludzie jeszcze nie dojrzeli i nie wiedzą o co Ci chodzi. Wtedy 300 wejść to bardzo dobry wynik. Jednak przeważnie jest tak, że zmieniając odrobinę słowa kluczowe naszej strony możemy znacznie zwiększyć jej popularność. Za chwilę to udowodnię.
W tej chwili powinny Cię już nękać pewne pytania natury egzystencjonalnej: skąd mam wiedzieć które frazy są częściej szukane niż inne, jak on udowodni że to faktycznie działa, po co on o tym pisze...
Zacznę od końca.. Po co o tym piszę? Ponieważ chcę podnieść popularność mojej strony! Skąd masz wiedzieć które frazy są częściej wpisywane niż inne? Zajrzyj tutaj. Tak, nie mylisz się, to znowu Google. Dokładnie jest to dodatek do Google AdWoords o nazwie KeywordTool. To narzędzie wyświetla nam ile razy wpisana przez nas fraza była wpisywana przez internautów w ubiegłym miesiącu oraz pokazuje przewidywalną średnią liczbę jej wyszukiwań w tym miesiącu. Dodatkowo podpowiada frazy podobne lub zbliżone, które mają wysoką liczbę wyszukiwań. Czy widzisz już jak można to wykorzystać? Przed chwilą napisałem, że piszę ten post aby moja strona wzrosła na popularności. Napisałem tak, ponieważ fraza "pozycjonowanie" w listopadzie 2008 była wyszukiwana 673 000 razy! Spójrz na poniższy zrzut:
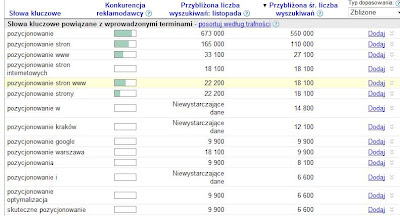
Może się wydawać, że przy tylu stronach w internecie to i tak nic nie zmienia, ale zmienia. Spróbuj na próbę wpisać kilka fraz powiązanych z Twoją stroną i zobacz ile dla nich jest wyszukiwań w ciągu miesiąca. Pomyśl na jakie, bardziej korzystne frazy mógłbyś je zamienić. Jak widzisz w temacie postu mam "Pozycjonowanie stron". Początkowo chciałem tam umieścić "Pozycjonowanie strony" ale spójrz na powyższe wyniki. Gdybym wpisał "Pozycjonowanie strony" to miałbym dla tej frazy tylko jakieś 22 200 wyszukań, wpisując "Pozycjonowanie stron" zwiększyłem znacznie swoją szansę na odwiedziny, ponieważ ta fraza była wyszukiwana 165 000 razy. Gdybym nie zmienił tej jednej literki pomyśl jak bardzo zostałbym w tyle. Jak to można wykorzystać? Ja np. jeżeli mam kilka pomysłów na posty a czasu tylko na napisanie jednego to sprawdzam jaki temat jest najbardziej pożądany przez internautów. To narzędzie daje wiele możliwości, wystarczy tylko pomyśleć.
Co ciekawsze Google KeywordTool można wykorzystywać nie tylko do pozycjonowania stron lub badania aktywności słów danych kluczowych. Zobacz do czego wykorzystuje je Piotr Majewski, znany biznesmen e-marketingowy:
W tej chwili powinny Cię już nękać pewne pytania natury egzystencjonalnej: skąd mam wiedzieć które frazy są częściej szukane niż inne, jak on udowodni że to faktycznie działa, po co on o tym pisze...
Zacznę od końca.. Po co o tym piszę? Ponieważ chcę podnieść popularność mojej strony! Skąd masz wiedzieć które frazy są częściej wpisywane niż inne? Zajrzyj tutaj. Tak, nie mylisz się, to znowu Google. Dokładnie jest to dodatek do Google AdWoords o nazwie KeywordTool. To narzędzie wyświetla nam ile razy wpisana przez nas fraza była wpisywana przez internautów w ubiegłym miesiącu oraz pokazuje przewidywalną średnią liczbę jej wyszukiwań w tym miesiącu. Dodatkowo podpowiada frazy podobne lub zbliżone, które mają wysoką liczbę wyszukiwań. Czy widzisz już jak można to wykorzystać? Przed chwilą napisałem, że piszę ten post aby moja strona wzrosła na popularności. Napisałem tak, ponieważ fraza "pozycjonowanie" w listopadzie 2008 była wyszukiwana 673 000 razy! Spójrz na poniższy zrzut:

Może się wydawać, że przy tylu stronach w internecie to i tak nic nie zmienia, ale zmienia. Spróbuj na próbę wpisać kilka fraz powiązanych z Twoją stroną i zobacz ile dla nich jest wyszukiwań w ciągu miesiąca. Pomyśl na jakie, bardziej korzystne frazy mógłbyś je zamienić. Jak widzisz w temacie postu mam "Pozycjonowanie stron". Początkowo chciałem tam umieścić "Pozycjonowanie strony" ale spójrz na powyższe wyniki. Gdybym wpisał "Pozycjonowanie strony" to miałbym dla tej frazy tylko jakieś 22 200 wyszukań, wpisując "Pozycjonowanie stron" zwiększyłem znacznie swoją szansę na odwiedziny, ponieważ ta fraza była wyszukiwana 165 000 razy. Gdybym nie zmienił tej jednej literki pomyśl jak bardzo zostałbym w tyle. Jak to można wykorzystać? Ja np. jeżeli mam kilka pomysłów na posty a czasu tylko na napisanie jednego to sprawdzam jaki temat jest najbardziej pożądany przez internautów. To narzędzie daje wiele możliwości, wystarczy tylko pomyśleć.
Co ciekawsze Google KeywordTool można wykorzystywać nie tylko do pozycjonowania stron lub badania aktywności słów danych kluczowych. Zobacz do czego wykorzystuje je Piotr Majewski, znany biznesmen e-marketingowy:
Htaccess redirect, czyli skutecznie i proste przekierowania
Czasami potrzebujemy przekierować link pod daną stronę aby wskazywał inną, jednak chcemy to zrobić bez ingerowania w nasze pliki html lub php. Możemy to zrobić bardzo łatwo za pomocą pliku .htaccess, który umieszczamy w głównym katalogu naszego serwera. Oczywiście serwer musi mieć włączoną obsługę tych plików.
Poniższy przykład przedstawia dwa przekierowania. Chcemy przekierować adres wskazujący na stary post tak aby otwierała się strona z nowym postem. W drugim przykładzie chcemy przekierować odnośniki ze starego tematu na nowy. Nic prostszego. Wystarczy następujący wpis umieścić w naszym pliku .htaccess:
Poniższy przykład przedstawia dwa przekierowania. Chcemy przekierować adres wskazujący na stary post tak aby otwierała się strona z nowym postem. W drugim przykładzie chcemy przekierować odnośniki ze starego tematu na nowy. Nic prostszego. Wystarczy następujący wpis umieścić w naszym pliku .htaccess:
Redirect permanent /posts/old_post.php /posts/new_post.php
Redirect permanent /subjects/old_sub.php /subjects/new_sub.php
Redirect permanent /subjects/old_sub.php /subjects/new_sub.php
Tworzenie własnego ekranu powitalnego w GRUB
W poprzednim poście pisałem jak wstawić tło w GRUBie. Pisałem również, że dosyć trudno znaleźć przygotowane tła po ten program. Tym razem napiszę jak można samemu zrobić takiego tło.
Grub narzuca wyświetlanym grafikom wiele ograniczeń jeśli chodzi o rozdzielczość i ilość kolorów. Nie możliwe jest również przesuwanie menu, które znajduję się w prostokącie w górnej części ekranu. Pod spodem znajdują się instrukcje. Podczas przygotowywania tła należy górną część obrazka zostawić dosyć prostą i mało kolorową, np. niebo a skupić się na ozdabianiu dolnej części. Chodzi tu o to, że tekst jest wyświetlanym w górnej części, więc skomplikowane kształty tła mogłyby sprawić, że tekst stanie się nieczytelny.
Wymagania obrazów tła:
- rozdzielczość 640x480;
- format .xpm (może być spakowany gzipem);
- nie więcej niż 14 kolorów;
Może 14 kolorów wydaję się mało ale można z tyloma kolorami zrobić wiele zaskakujących rzeczy.
OK, mamy dwie możliwość; albo tworzymy jakiś obrazek ręcznie w GIMPie lub innym edytorze, albo odnajdujemy interesujący obrazek w necie i go obrabiamy. W pierwszym przypadku sugeruję aby od razu utworzyć nowy plik o rozdzielczości 640x480 i używać jak najmniej kolorów. Nie musi to być oczywiście 14, później je i tak zredukujemy.
Jeżeli mamy już nasz obrazek wstępnie przygotowany (nazwijmy go tlo.png) to teraz musimy sprawdzamy czy mamy pakiet narzędzi o nazwie ImageMagick. W większości dystrybucji jest on domyślnie zainstalowany. Pozostałe polecenia wydajemy jako root.
apt-get install imagemagick
Gdy już mamy imagemagick wydajemy polecenie:
convert tlo.png -colors 14 -resize 640x480 tlo.xpm
Polecenie convert po rozszerzeniu rozpoznaje format obrabianego pliku. Format xpm też jest mu znany. Jeżeli nasz obrazek już miał rozdzielczość 640x480 to już nie musimy wydawać komendy -resize 640x480.
Następnie możemy spakować nasz nowy plik i skopiować go do /boot/grub. Pakowanie obrazka nie jest konieczne ale dzięki temu oszczędzamy miejsce, więc nie zaszkodzi. Szczególnie przydatne jeżeli nasz program rozruchowy znajduje się na dyskietce. Więc wykonujemy następujące polecenia:
gzip tlo.xpm
cp tlo.xpm.gz /boot/grub
Teraz do pliku grub.conf dopisujemy lub edytujemy następujący wiersz:
Teraz sprawdzamy czy wszystko działa ponownie uruchamiając komputer.
Grub narzuca wyświetlanym grafikom wiele ograniczeń jeśli chodzi o rozdzielczość i ilość kolorów. Nie możliwe jest również przesuwanie menu, które znajduję się w prostokącie w górnej części ekranu. Pod spodem znajdują się instrukcje. Podczas przygotowywania tła należy górną część obrazka zostawić dosyć prostą i mało kolorową, np. niebo a skupić się na ozdabianiu dolnej części. Chodzi tu o to, że tekst jest wyświetlanym w górnej części, więc skomplikowane kształty tła mogłyby sprawić, że tekst stanie się nieczytelny.
Wymagania obrazów tła:
- rozdzielczość 640x480;
- format .xpm (może być spakowany gzipem);
- nie więcej niż 14 kolorów;
Może 14 kolorów wydaję się mało ale można z tyloma kolorami zrobić wiele zaskakujących rzeczy.
OK, mamy dwie możliwość; albo tworzymy jakiś obrazek ręcznie w GIMPie lub innym edytorze, albo odnajdujemy interesujący obrazek w necie i go obrabiamy. W pierwszym przypadku sugeruję aby od razu utworzyć nowy plik o rozdzielczości 640x480 i używać jak najmniej kolorów. Nie musi to być oczywiście 14, później je i tak zredukujemy.
Jeżeli mamy już nasz obrazek wstępnie przygotowany (nazwijmy go tlo.png) to teraz musimy sprawdzamy czy mamy pakiet narzędzi o nazwie ImageMagick. W większości dystrybucji jest on domyślnie zainstalowany. Pozostałe polecenia wydajemy jako root.
apt-get install imagemagick
Gdy już mamy imagemagick wydajemy polecenie:
convert tlo.png -colors 14 -resize 640x480 tlo.xpm
Polecenie convert po rozszerzeniu rozpoznaje format obrabianego pliku. Format xpm też jest mu znany. Jeżeli nasz obrazek już miał rozdzielczość 640x480 to już nie musimy wydawać komendy -resize 640x480.
Następnie możemy spakować nasz nowy plik i skopiować go do /boot/grub. Pakowanie obrazka nie jest konieczne ale dzięki temu oszczędzamy miejsce, więc nie zaszkodzi. Szczególnie przydatne jeżeli nasz program rozruchowy znajduje się na dyskietce. Więc wykonujemy następujące polecenia:
gzip tlo.xpm
cp tlo.xpm.gz /boot/grub
Teraz do pliku grub.conf dopisujemy lub edytujemy następujący wiersz:
splahimage=(hd0,0) /boot/grub/tlo.xpm.gzTeraz sprawdzamy czy wszystko działa ponownie uruchamiając komputer.
Wyświetlanie tła w bootloaderze GRUB
Jeżeli nam się nie podoba domyślny wygląd naszego GRUBA to możemy go bardzo łatwo zmienić. Co prawda trudno jest znaleźć odpowiednio przygotowane tła dla tego programu, ale dla chcącego nic trudnego. Przykładowe miniaturki takich obrazów można np. zobaczyć na stronie ruslug.rutgers.edu/~mcgrof/grub-images/images/ a pobrać je można ze strony ruslug.rutgers.edu/~mcgrof/grub-images/images/working-splashimages/.
Dla tego przykładu posłużymy się plikiem DigitalAnGeL.xpm.gz.
Logujemy się na roota i kopiujemy ten plik do katalogu /boot/grub:
cp DigitalAnGeL.xpm.gz /boot/grub
Następnie edytujemy plik /boot/grub/grub.conf i dodajemy tam lub edytujemy następujący wpis:
Oczywiście w zależności od dystrybucji katalog boot może znajdować się gdzieś indziej, edytujemy wtedy odpowiednio powyższe wpisy.
Dla tego przykładu posłużymy się plikiem DigitalAnGeL.xpm.gz.
Logujemy się na roota i kopiujemy ten plik do katalogu /boot/grub:
cp DigitalAnGeL.xpm.gz /boot/grub
Następnie edytujemy plik /boot/grub/grub.conf i dodajemy tam lub edytujemy następujący wpis:
splashimage=(hd0,0) /boot/grub/DigitalAnGeL.xpm.gzOczywiście w zależności od dystrybucji katalog boot może znajdować się gdzieś indziej, edytujemy wtedy odpowiednio powyższe wpisy.
Google SketchUp, czyli łatwe modelowanie projektów 3D
Pojawiła się nowa aplikacja firmy z Mountain View. Teraz za pomocą Google SketchUp możemy tworzyć proste lub zaawansowane projekty 3D i wszystko za darmo.
A tutaj już bardziej zaawansowany przykład. Projektujemy traktor:
A tutaj już bardziej zaawansowany przykład. Projektujemy traktor:
piątek, 19 grudnia 2008
Jak sprawdzić nazwę i numer danego portu na Linuxie
W nawiązaniu do poprzedniego postu postanowiłem umieścić dużo łatwiejszy sposób sprawdzania nazwy lub numeru danego portu. Wszystko co nam do tego potrzebne to Linux.
Linux w pliku /etc/services trzyma najczęściej używane przez niego portu wraz z nazwami, więc jeżeli wyleciał nam numer lub nazwa danego portu wystarczy otworzyć konsolę i w zależności czy interesuje nas nazwa czy numer, wpisać:
grep ssh /etc/services
i analogicznie jeżeli znamy numer a nie wiemy co to za port:
grep 22 /etc/services
Linux w pliku /etc/services trzyma najczęściej używane przez niego portu wraz z nazwami, więc jeżeli wyleciał nam numer lub nazwa danego portu wystarczy otworzyć konsolę i w zależności czy interesuje nas nazwa czy numer, wpisać:
grep ssh /etc/services
i analogicznie jeżeli znamy numer a nie wiemy co to za port:
grep 22 /etc/services
Lista powszechnie używanych portów
Jeżeli nam wyleciał numer jakiegoś portu to na pewno go znajdziecie na tej stronie:
www.iana.org/assignments/port-numbers
Początkowo chciałem przekopiować tą listę na mojego bloga ale to by go bardzo obciążyło. Przekonajcie się sami.
www.iana.org/assignments/port-numbers
Początkowo chciałem przekopiować tą listę na mojego bloga ale to by go bardzo obciążyło. Przekonajcie się sami.
VirtualBox 2.1 czyli bezpłatny konkurent VWware'a
Doczekaliśmy się kolejnego wydania popularnego programu do wirtualizacji VirtualBox, tym razem wersji 2.1. Coraz większa popularność tego oprogramowania jest spowodowana przede wszystkim tym, że jest on darmowy. Mimo pozorów ta zaleta staję się coraz mniej zauważalna, ponieważ pod względem funkcjonalności VirtualBox zaczyna doganiać swojego komercyjnego kolegę, czyli VMware Workstation 6.5. Programiści z Sun Microsystem odwalili kawał dobrej roboty.
To co w nowej wersji uległo znaczniej poprawie to obsługa sprzętowa dla procesorów Intela oraz AMD. Również rozrosła się lista systemów gościnnych, z której to listy, możemy uruchamiać systemy z obsługą grafiki 3D OpenGL (funkcja obecnie w fazie beta). Dla systemów z listy gości możemy nawet instalować 64-bitowe systemy na 32-bitowych systemach bazowych, jednak ta funkcja jest do tej pory również w fazie beta. Kolejną zaletą jest poprawiona obsługa interfejsów sieciowych.
Dla ludzi których przekonały zalety VirtualBox'a mam jeszcze jedną dobrą nowinę - nowy VirtualBox obsługuje maszyny wirtualne stworzone na innym oprogramowaniu, czyli np. VHD Microsoftu, czy VMDK VMware'a, więc nikt nie będzie musiał tworzyć na nowo obrazów tworzonych do tej pory w innych programach.
Na stronie www.virtualbox.org/wiki/Guest_OSes znajduję się lista wszystkich obsługiwanych systemów. Jak widzicie jest ona całkiem pokaźna.
Natomiast oprogramowanie można ściągnąć ze strony: www.virtualbox.org/wiki/Downloads
To co w nowej wersji uległo znaczniej poprawie to obsługa sprzętowa dla procesorów Intela oraz AMD. Również rozrosła się lista systemów gościnnych, z której to listy, możemy uruchamiać systemy z obsługą grafiki 3D OpenGL (funkcja obecnie w fazie beta). Dla systemów z listy gości możemy nawet instalować 64-bitowe systemy na 32-bitowych systemach bazowych, jednak ta funkcja jest do tej pory również w fazie beta. Kolejną zaletą jest poprawiona obsługa interfejsów sieciowych.
Dla ludzi których przekonały zalety VirtualBox'a mam jeszcze jedną dobrą nowinę - nowy VirtualBox obsługuje maszyny wirtualne stworzone na innym oprogramowaniu, czyli np. VHD Microsoftu, czy VMDK VMware'a, więc nikt nie będzie musiał tworzyć na nowo obrazów tworzonych do tej pory w innych programach.
Na stronie www.virtualbox.org/wiki/Guest_OSes znajduję się lista wszystkich obsługiwanych systemów. Jak widzicie jest ona całkiem pokaźna.
Natomiast oprogramowanie można ściągnąć ze strony: www.virtualbox.org/wiki/Downloads
czwartek, 18 grudnia 2008
wtorek, 16 grudnia 2008
Polski programista pomaga w łataniu Google Chrom
Google twierdzi, że przeglądarka Chrome jest otwartym i wolnym projektem. Jednak do tej pory pracowali nad nią tylko inżynierowie Google'a. Niezależni programiści mogli co najwyżej dostarczać łatki, które przed włączeniem do repozytorium kodu były rozpatrywane przez kierowników projektu z Mountain View. Teraz jednak to się zmieniło – do grona osób mających prawo do bezpośredniego wprowadzania zmian do Chrome'a dołączyła pierwsza osoba z zewnątrz – Paweł Hajdan (junior), student informatyki Uniwersytetu Warszawskiego.
Paweł otrzymał ten przywilej dzięki swojej niezwykłej aktywności w ramach projektu. Evan Martin, jeden z głównych twórców Chrome'a napisał na łamach firmowego bloga: „w swoim wolnym czasie [Paweł Hajdan – przyp. red.] dostarczył on mnóstwo kodu wysokiej jakości, dzięki któremu będzie można uruchomić Chromium na innych niż Windows platformach”. Uzyskanie takiego przywileju nie jest łatwe – zainteresowany musi dowieść, że naprawdę zależy mu na Chromium i osiągnięciu celów projektu.
„Przywilej ten nadajemy w oczekiwaniu pewnej odpowiedzialności. Dostępu nie uzyska po prostu ten, kto potrafi wprowadzać zmiany do repozytorium. Musi on być w stanie współpracować z zespołem, umieć znaleźć najlepszych ludzi do zrecenzowania kodu, sam dostarczać kod najwyższej jakości i wreszcie do końca rozwiązywać pojawiające się problemy” – dodał Martin.
Zgodnie z wytycznymi Google, osoba która ubiega się o prawo do bezpośredniego dostępu do kodu musi „dostarczyć od 10 do 20 nietrywialnych poprawek, które zostaną ocenione przez przynajmniej trzy różne osoby”.
Pawłowi serdecznie gratulujemy tego sukcesu i mamy nadzieję, że dzięki jego pracy Chrome już wkrótce zadebiutuje na Linuksie i Mac OS X.
Źródło: Webhosting.pl
Paweł otrzymał ten przywilej dzięki swojej niezwykłej aktywności w ramach projektu. Evan Martin, jeden z głównych twórców Chrome'a napisał na łamach firmowego bloga: „w swoim wolnym czasie [Paweł Hajdan – przyp. red.] dostarczył on mnóstwo kodu wysokiej jakości, dzięki któremu będzie można uruchomić Chromium na innych niż Windows platformach”. Uzyskanie takiego przywileju nie jest łatwe – zainteresowany musi dowieść, że naprawdę zależy mu na Chromium i osiągnięciu celów projektu.
„Przywilej ten nadajemy w oczekiwaniu pewnej odpowiedzialności. Dostępu nie uzyska po prostu ten, kto potrafi wprowadzać zmiany do repozytorium. Musi on być w stanie współpracować z zespołem, umieć znaleźć najlepszych ludzi do zrecenzowania kodu, sam dostarczać kod najwyższej jakości i wreszcie do końca rozwiązywać pojawiające się problemy” – dodał Martin.
Zgodnie z wytycznymi Google, osoba która ubiega się o prawo do bezpośredniego dostępu do kodu musi „dostarczyć od 10 do 20 nietrywialnych poprawek, które zostaną ocenione przez przynajmniej trzy różne osoby”.
Pawłowi serdecznie gratulujemy tego sukcesu i mamy nadzieję, że dzięki jego pracy Chrome już wkrótce zadebiutuje na Linuksie i Mac OS X.
Źródło: Webhosting.pl
Cisco twierdzi, że 90% maili to spam
90% maili generujących ruch w Internecie to spam. Pochodzą one głównie z zarażonych komputerów-zombie. Takie wyniki dał raport, przedstawiony przez firmę Cisco. W badaniu wzięto pod uwagę ponad 200 miliardów wiadomości e-mail, z których 90% okazało się być spamem.
Patrick Petersom, odpowiedzialny w Cisco za kwestie dotyczące bezpieczeństwa, powiedział, że z każdym rokiem można zauważyć coraz większą przebiegłość hakerów. Stosują oni coraz to nowsze sposoby wykorzystania exploitów, których ofiarą padają internauci, sieci, a także Internet, jako ogół.
Większość spamu pochodziło z terenu Stanów Zjednoczonych, których mieszkańcy należą do większości ofiar takich działań. Ma to również związek z tym, że najwięcej zarażonych komputerów znajduje się właśnie tam. Na drugim miejscu jeśli chodzi o liczbę wysyłanego spamu znalazła się Tajlandia (17,2%), na trzecim Turcja (9,2%), a na czwartym Rosja (8%). Dwa ostatnie miejsca są wynikiem tego, że spamerzy często używają serwerów, które znajdują się właśnie w tych krajach.
Głównym celem hakerów padają słabo zabezpieczone konta pocztowe, które po złamaniu ich hasła są wykorzystywane do rozsyłania spamu. Według Cisco hakerzy wybrali głównie w ten sposób działania, gdyż użytkownicy posiadają coraz większą wiedzę odnośnie sieci i bardzo ostrożnie podchodzą do odnośników czy wiadomości pochodzących z podejrzanego źródła.
Źródło: IDG.pl
Patrick Petersom, odpowiedzialny w Cisco za kwestie dotyczące bezpieczeństwa, powiedział, że z każdym rokiem można zauważyć coraz większą przebiegłość hakerów. Stosują oni coraz to nowsze sposoby wykorzystania exploitów, których ofiarą padają internauci, sieci, a także Internet, jako ogół.
Większość spamu pochodziło z terenu Stanów Zjednoczonych, których mieszkańcy należą do większości ofiar takich działań. Ma to również związek z tym, że najwięcej zarażonych komputerów znajduje się właśnie tam. Na drugim miejscu jeśli chodzi o liczbę wysyłanego spamu znalazła się Tajlandia (17,2%), na trzecim Turcja (9,2%), a na czwartym Rosja (8%). Dwa ostatnie miejsca są wynikiem tego, że spamerzy często używają serwerów, które znajdują się właśnie w tych krajach.
Głównym celem hakerów padają słabo zabezpieczone konta pocztowe, które po złamaniu ich hasła są wykorzystywane do rozsyłania spamu. Według Cisco hakerzy wybrali głównie w ten sposób działania, gdyż użytkownicy posiadają coraz większą wiedzę odnośnie sieci i bardzo ostrożnie podchodzą do odnośników czy wiadomości pochodzących z podejrzanego źródła.
Źródło: IDG.pl
czwartek, 11 grudnia 2008
Google Chrome 1.0 - finalna wersja już u nas
Przypomnijmy, że przeglądarka Google Chrome w wersji Beta ujrzała światło dzienne po raz pierwszy na początku września tego roku. Jest to darmowe rozwiązanie, które ma być alternatywą dla takich produktów jak Internet Explorer, Firefox czy Opera. Niestety po początkowych sukcesach i olbrzymim zainteresowaniu ze strony użytkowników aplikacja straciła w ostatnim czasie na popularności, między innymi ze względu na sporą ilość błędów.
Dzisiaj informowaliśmy (11 grudnia 2008) - opierając się na informacjach podawanych przez Marissę Mayer, wiceprezes firmy Google - że Google Chrome wkrótce wychodzi z fazy Beta. Finalnej wersji można było spodziewać się na początku przyszłego roku, prawdopodobnie w styczniu. Słowa te okazały się jedynie zasłoną dymną dla prawdziwej daty premiery. Przeglądarka Google Chrome 1.0 jest dostępna już dzisiaj!
Firma Google zdecydowała się zdjąć etykietę Beta po ponad 100 dniach ciężkiej pracy nad poprawieniem stabilności i wydajności przeglądarki.
Google Chrome jest przeglądarką zaprojektowaną dla nowej formuły Internetu, który od kilku lat rozwija się znacznie bardziej dynamicznie. Dawniej strony internetowe były połączeniem tekstu i prostej grafiki. Dzisiaj stają się potężnymi platformami multimedialnymi, zawierającymi między innymi wideo i gry oraz narzędzia do współpracy online. Google pracując nad przeglądarką Chrome skupiał się głównie na tym, aby umożliwiała ona użytkownikom surfowanie po sieci szybciej, łatwiej i stabilniej" - czytamy w komunikacie wydanym z okazji premiery wersji 1.0.
Owe 100 dni pracy doprowadziły - według przedstawicieli Google'a - do znacznego ulepszenia przeglądarki. Finalna wersja o numerze 1.0.154.36 doczekała się usprawnień w kilku kluczowych obszarach:
Stabilność i wydajność
Programiści skupili się na poprawieniu wydajności, przywiązując także uwagę do stabilności aplikacji podczas przeglądania materiałów audio i wideo.
Większa szybkość
Przeglądarka - w porównaniu do wersji Beta - uruchamia się i ładuje strony znacznie szybciej. Efekt taki udało się uzyskać dzięki ulepszeniom wprowadzonym do silnika V8 JavaScript.
Menedżer zakładek i kontrola prywatności
Zakładki przeglądarki oferują większe możliwości, łatwiej jest również nimi zarządzać. Zagadnienia dotyczące prywatności zostały pogrupowane i znajdują się w jednym miejscu wraz ze szczegółowymi wyjaśnieniami.
Przedstawiciele Google uzasadniając rezygnację z etykiety Beta podkreślają, że było to możliwe dzięki osiągnięciu założonych celów w zakresie zwiększenia wydajności i stabilności. Programistów czeka jednak ciężka praca związana z wprowadzaniem nowych funkcji (na przykład automatyczne wypełnianie formularzy i obsługa RSS), usprawnieniami aplikacji oraz przygotowaniem wersji dla systemów Mac i Linux.
Wersję finalną można pobrać tutaj.
Źródło: IDG.pl
Dzisiaj informowaliśmy (11 grudnia 2008) - opierając się na informacjach podawanych przez Marissę Mayer, wiceprezes firmy Google - że Google Chrome wkrótce wychodzi z fazy Beta. Finalnej wersji można było spodziewać się na początku przyszłego roku, prawdopodobnie w styczniu. Słowa te okazały się jedynie zasłoną dymną dla prawdziwej daty premiery. Przeglądarka Google Chrome 1.0 jest dostępna już dzisiaj!
Firma Google zdecydowała się zdjąć etykietę Beta po ponad 100 dniach ciężkiej pracy nad poprawieniem stabilności i wydajności przeglądarki.
Google Chrome jest przeglądarką zaprojektowaną dla nowej formuły Internetu, który od kilku lat rozwija się znacznie bardziej dynamicznie. Dawniej strony internetowe były połączeniem tekstu i prostej grafiki. Dzisiaj stają się potężnymi platformami multimedialnymi, zawierającymi między innymi wideo i gry oraz narzędzia do współpracy online. Google pracując nad przeglądarką Chrome skupiał się głównie na tym, aby umożliwiała ona użytkownikom surfowanie po sieci szybciej, łatwiej i stabilniej" - czytamy w komunikacie wydanym z okazji premiery wersji 1.0.
Owe 100 dni pracy doprowadziły - według przedstawicieli Google'a - do znacznego ulepszenia przeglądarki. Finalna wersja o numerze 1.0.154.36 doczekała się usprawnień w kilku kluczowych obszarach:
Stabilność i wydajność
Programiści skupili się na poprawieniu wydajności, przywiązując także uwagę do stabilności aplikacji podczas przeglądania materiałów audio i wideo.
Większa szybkość
Przeglądarka - w porównaniu do wersji Beta - uruchamia się i ładuje strony znacznie szybciej. Efekt taki udało się uzyskać dzięki ulepszeniom wprowadzonym do silnika V8 JavaScript.
Menedżer zakładek i kontrola prywatności
Zakładki przeglądarki oferują większe możliwości, łatwiej jest również nimi zarządzać. Zagadnienia dotyczące prywatności zostały pogrupowane i znajdują się w jednym miejscu wraz ze szczegółowymi wyjaśnieniami.
Przedstawiciele Google uzasadniając rezygnację z etykiety Beta podkreślają, że było to możliwe dzięki osiągnięciu założonych celów w zakresie zwiększenia wydajności i stabilności. Programistów czeka jednak ciężka praca związana z wprowadzaniem nowych funkcji (na przykład automatyczne wypełnianie formularzy i obsługa RSS), usprawnieniami aplikacji oraz przygotowaniem wersji dla systemów Mac i Linux.
Wersję finalną można pobrać tutaj.
Źródło: IDG.pl
sobota, 29 listopada 2008
Skróty klawiaturowe systemu Windows
Były skróty stosowane w Linuxie, więc aby nie zostawiać Windowsa bez komentarza podaję skróty klawiaturowe do tego drugiego:
Skróty klawiaturowe łatwego dostępu:
Prawy klawisz SHIFT przez osiem sekund
Włączyć lub wyłączyć funkcję Klawisze filtru
Klawisze lewy ALT+lewy SHIFT+PRINT SCREEN (lub PRTSCRN)
Włączyć lub wyłączyć funkcję Duży kontrast
Klawisze lewy ALT+lewy SHIFT+NUM LOCK
Włączyć lub wyłączyć funkcję Klawisze myszy
Klawisz SHIFT pięć razy
Włączyć lub wyłączyć funkcję Klawisze trwałe
Klawisz NUM LOCK przez pięć sekund
Włączyć lub wyłączyć funkcję Klawisze przełączające
Windows Klawisz logo +U
Otworzyć Centrum ułatwień dostępu
Ogólne skróty klawiaturowe:
F1
Wyświetlić Pomoc
CTRL+C
Skopiować zaznaczony element
CTRL+X
Wyciąć zaznaczony element
CTRL+V
Wkleić zaznaczony element
CTRL+Z
Cofnąć akcję
CTRL+Y
Wykonać ponownie akcję
DELETE
Usunąć zaznaczony element i przenieść go do Kosza
SHIFT+DELETE
Usunąć zaznaczony element bez przenoszenia go najpierw do Kosza
F2
Zmienić nazwę wybranego elementu
CTRL+STRZAŁKA W PRAWO
Przenieść kursor na początek następnego wyrazu
CTRL+STRZAŁKA W LEWO
Przenieść kursor na początek poprzedniego wyrazu
CTRL+STRZAŁKA W DÓŁ
Przenieść kursor na początek następnego akapitu
CTRL+STRZAŁKA W GÓRĘ
Przenieść kursor na początek poprzedniego akapitu
CTRL+SHIFT z klawiszem strzałki
Zaznaczyć blok tekstu
SHIFT z dowolnym klawiszem strzałki
Zaznaczyć kilka elementów w oknie lub na pulpicie albo zaznaczyć tekst w dokumencie
CTRL z dowolnym klawiszem strzałki + SPACJA
Zaznaczyć kilka pojedynczych elementów w oknie lub na pulpicie
CTRL+A
Zaznaczyć wszystkie elementy w dokumencie lub oknie
F3
Wyszukać plik lub folder
ALT+ENTER
Wyświetlić właściwości wybranego elementu
ALT+F4
Zamknąć aktywny element lub zakończyć pracę z aktywnym programem
ALT+SPACJA
Otworzyć menu skrótów aktywnego okna
CTRL+F4
Zamknąć aktywny dokument (w programach, w których może być jednocześnie otwartych wielu dokumentów)
ALT+TAB
Przełączyć między otwartymi elementami
CTRL+ALT+TAB
Korzystając z klawiszy strzałek, przełączyć się między otwartymi elementami
Windows Klawisz logo +TAB
Przechodzić między kolejnymi programami na pasku zadań przy użyciu funkcji Flip 3-D systemu Windows
CTRL+klawisz logo Windows +TAB
Korzystając z klawiszy strzałek, przechodzić między kolejnymi programami na pasku zadań za pomocą funkcji Flip 3-D systemu Windows
ALT+ESC
Przechodzić między elementami w kolejności, w jakiej zostały otwarte
F6
Przechodzić między kolejnymi elementami okna lub pulpitu
F4
Wyświetlić listę paska adresu w Eksploratorze Windows
SHIFT+F10
Wyświetlić menu skrótów wybranego elementu
CTRL+ESC
Otworzyć menu Start
ALT+podkreślona litera
Wyświetlić odpowiednie menu
ALT+podkreślona litera
Wykonać polecenie menu (lub inne podkreślone polecenie)
F10
Uaktywnić pasek menu w aktywnym programie
STRZAŁKA W PRAWO
Otworzyć następne menu z prawej strony lub otworzyć podmenu
STRZAŁKA W LEWO
Otworzyć następne menu z lewej strony lub zamknąć podmenu
F5
Odświeżyć aktywne okno
ALT+STRZAŁKA W GÓRĘ
Wyświetlić folder znajdujący się o jeden poziom wyżej w Eksploratorze Windows
ESC
Anulować bieżące zadanie
CTRL+SHIFT+ESC
Otworzyć Menedżera zadań
SHIFT podczas wkładania dysku CD
Zapobiec automatycznemu odtwarzaniu dysku CD
Skróty klawiaturowe w oknach dialogowych:
CTRL+TAB
Przejść do następnej karty
CTRL+SHIFT+TAB
Przejść do poprzedniej karty
TAB
Przejść do następnej opcji
SHIFT+TAB
Przejść do poprzedniej opcji
ALT+podkreślona litera
Wykonać polecenie lub wybrać opcję skojarzoną z tą literą
ENTER
Zastępuje kliknięcie myszy w przypadku wielu wybranych poleceń.
SPACJA
Zaznaczyć lub wyczyścić pole wyboru, jeśli aktywna opcja jest polem wyboru
Klawisze strzałek
Zaznaczyć przycisk, jeśli aktywna opcja jest grupą przycisków opcji
F1
Wyświetlanie pomocy
F4
Wyświetlić elementy na aktywnej liście
BACKSPACE
Otworzyć folder znajdujący się o jeden poziom wyżej, jeśli w oknie dialogowym Zapisz jako lub Otwórz jest zaznaczony folder
Skróty klawiaturowe używane z klawiaturami firmy Microsoft:
Windows Klawisz logo
Otworzyć lub zamknąć menu Start
Windows Klawisz logo +PAUSE
Wyświetlić okno dialogowe Właściwości systemu
Windows Klawisz logo +D
Wyświetlić pulpit
Windows Klawisz logo +M
Zminimalizować wszystkie okna
Windows Klawisz logo +SHIFT+M
Przywrócić zminimalizowane okna na pulpit
Windows Klawisz logo +E
Otworzyć folder Komputer
Windows Klawisz logo +F
Wyszukać plik lub folder
CTRL+klawisz logo Windows +F
Wyszukać komputery (jeśli użytkownik pracuje w sieci)
Windows Klawisz logo +L
Zablokować komputer lub przełączyć użytkowników
Windows Klawisz logo +R
Otworzyć okno dialogowe Uruchamianie
Windows Klawisz logo +T
Przechodzić między programami na pasku zadań
Windows Klawisz logo +TAB
Przechodzić między kolejnymi programami na pasku zadań przy użyciu funkcji Flip 3-D systemu Windows
CTRL+klawisz logo Windows +TAB
Korzystając z klawiszy strzałek, przechodzić między kolejnymi programami na pasku zadań za pomocą funkcji Flip 3-D systemu Windows
Windows Klawisz logo +SPACJA
Wyświetlić wszystkie gadżety na pierwszym planie i wybrać pasek boczny systemu Windows
Windows Klawisz logo +G
Przechodzić między kolejnymi gadżetami na pasku bocznym
Windows Klawisz logo +U
Otworzyć Centrum ułatwień dostępu
Windows Klawisz logo +X
Otworzyć Centrum mobilności w systemie Windows
Windows Klawisz logo z dowolnym klawiszem numerycznym
Otworzyć skrót menu Szybkie uruchamianie, który znajduje się na pozycji odpowiadającej klawiszowi numerycznemu. Na przykład klawisz logo Windows +1, aby uruchomić pierwszy skrót w menu Szybkie uruchamianie.
Skróty klawiaturowe Eksploratora Windows:
CTRL+N
Otworzyć nowe okno
END
Wyświetlić dolną część aktywnego okna
HOME
Wyświetlić górną część aktywnego okna
F11
Zmaksymalizować lub zminimalizować aktywne okno
NUM LOCK+GWIAZDKA (*) na klawiaturze numerycznej
Wyświetlić wszystkie podfoldery w wybranym folderze
NUM LOCK+ZNAK PLUS (+) na klawiaturze numerycznej
Wyświetlić zawartość wybranego folderu
NUM LOCK+ZNAK MINUS (-) na klawiaturze numerycznej
Zwinąć wybrany folder
STRZAŁKA W LEWO
Zwinąć bieżące zaznaczenie (jeśli jest rozwinięte) lub wybrać folder nadrzędny
ALT+STRZAŁKA W LEWO
Wyświetlić poprzedni folder
STRZAŁKA W PRAWO
Wyświetlić bieżące zaznaczenie (jeśli jest zwinięte) lub wybrać pierwszy podfolder
ALT+STRZAŁKA W PRAWO
Wyświetlić następny folder
ALT+D
Wybrać pasek adresu
Skróty klawiaturowe paska bocznego systemu Windows:
Windows Klawisz logo +SPACJA
Wyświetlić wszystkie gadżety na pierwszym planie i wybrać pasek boczny
Windows Klawisz logo +G
Przechodzić między kolejnymi gadżetami na pasku bocznym
TAB
Przechodzić między kolejnymi formantami paska bocznego
Skróty klawiaturowe Galerii fotografii systemu Windows:
CTRL+F
Otworzyć okienko Napraw
CTRL+P
Wydrukować wybrany obraz
ENTER
Wyświetlić wybrany obraz w większej skali
CTRL+I
Otworzyć lub zamknąć okienko szczegółów
CTRL+KROPKA (.)
Obrócić obraz zgodnie z ruchem wskazówek zegara
CTRL+PRZECINEK (,)
Obrócić obraz zgodnie przeciwnie do ruchu wskazówek zegara
F2
Zmienić nazwę wybranego elementu
CTRL+E
Wyszukać element
ALT+STRZAŁKA W LEWO
Przejść wstecz
ALT+STRZAŁKA W PRAWO
Przejść do przodu
ZNAK PLUS (+)
Powiększyć lub zmienić rozmiar miniatury obrazu
ZNAK MINUS (-)
Pomniejszyć lub zmienić rozmiar miniatury obrazu
CTRL+B
Optymalnie dopasować
STRZAŁKA W LEWO
Wybrać poprzedni element
STRZAŁKA W DÓŁ
Wybrać następny element lub wiersz
STRZAŁKA W GÓRĘ
Poprzedni element (Sztaluga) lub wiersz (Miniatura)
PAGE UP
Poprzedni ekran
PAGE DOWN
Następny ekran
HOME
Wybrać pierwszy element
END
Wybrać ostatni element
DELETE
Przenieść wybrany element do Kosza
SHIFT+DELETE
Trwale usunąć wybrany element
STRZAŁKA W LEWO
Zwinąć węzeł
STRZAŁKA W PRAWO
Rozwinąć węzeł
Skróty klawiaturowe do pracy z filmami wideo:
J
Przejść do poprzedniej klatki
K
Wstrzymać odtwarzanie
L
Przejść do następnej klatki
I
Ustawić punkt początkowy przycięcia
O
Ustawić punkt końcowy przycięcia
M
Podzielić klip
HOME
Zatrzymać i przewinąć do tyłu aż do punktu początkowego przycięcia
ALT+STRZAŁKA W PRAWO
Przejść do następnej klatki
ALT+STRZAŁKA W LEWO
Przejść do poprzedniej klatki
CTRL+K
Zatrzymać odtwarzanie i przewinąć do tyłu
CTRL+P
Odtworzyć od bieżącego miejsca
HOME
Przejść do punktu początkowego przycięcia
END
Przejść do punktu końcowego przycięcia
PAGE UP
Przejść do najbliższego punktu podziału przed bieżącą lokalizacją
PAGE DOWN
Przejść do najbliższego punktu podziału za bieżącą lokalizacją
Skróty klawiaturowe Podglądu pomocy systemu Windows:
ALT+C
Wyświetlić spis treści
ALT+N
Wyświetlić menu Ustawienia połączenia
F10
Wyświetlić menu Opcje
ALT+STRZAŁKA W LEWO
Przejść wstecz do poprzedniego (przeglądanego już) tematu
ALT+STRZAŁKA W PRAWO
Przejść do przodu do następnego (przeglądanego już) tematu
ALT+A
Wyświetlić stronę pomocy technicznej
ALT+HOME
Wyświetlić stronę główną Pomocy i obsługi technicznej
HOME
Przejść do początku tematu
END
Przejść do końca tematu
CTRL+F
Wyszukać bieżący temat
CTRL+P
Wydrukować temat
F3
Przejść do pola wyszukiwania
Skróty klawiaturowe łatwego dostępu:
Prawy klawisz SHIFT przez osiem sekund
Włączyć lub wyłączyć funkcję Klawisze filtru
Klawisze lewy ALT+lewy SHIFT+PRINT SCREEN (lub PRTSCRN)
Włączyć lub wyłączyć funkcję Duży kontrast
Klawisze lewy ALT+lewy SHIFT+NUM LOCK
Włączyć lub wyłączyć funkcję Klawisze myszy
Klawisz SHIFT pięć razy
Włączyć lub wyłączyć funkcję Klawisze trwałe
Klawisz NUM LOCK przez pięć sekund
Włączyć lub wyłączyć funkcję Klawisze przełączające
Windows Klawisz logo +U
Otworzyć Centrum ułatwień dostępu
Ogólne skróty klawiaturowe:
F1
Wyświetlić Pomoc
CTRL+C
Skopiować zaznaczony element
CTRL+X
Wyciąć zaznaczony element
CTRL+V
Wkleić zaznaczony element
CTRL+Z
Cofnąć akcję
CTRL+Y
Wykonać ponownie akcję
DELETE
Usunąć zaznaczony element i przenieść go do Kosza
SHIFT+DELETE
Usunąć zaznaczony element bez przenoszenia go najpierw do Kosza
F2
Zmienić nazwę wybranego elementu
CTRL+STRZAŁKA W PRAWO
Przenieść kursor na początek następnego wyrazu
CTRL+STRZAŁKA W LEWO
Przenieść kursor na początek poprzedniego wyrazu
CTRL+STRZAŁKA W DÓŁ
Przenieść kursor na początek następnego akapitu
CTRL+STRZAŁKA W GÓRĘ
Przenieść kursor na początek poprzedniego akapitu
CTRL+SHIFT z klawiszem strzałki
Zaznaczyć blok tekstu
SHIFT z dowolnym klawiszem strzałki
Zaznaczyć kilka elementów w oknie lub na pulpicie albo zaznaczyć tekst w dokumencie
CTRL z dowolnym klawiszem strzałki + SPACJA
Zaznaczyć kilka pojedynczych elementów w oknie lub na pulpicie
CTRL+A
Zaznaczyć wszystkie elementy w dokumencie lub oknie
F3
Wyszukać plik lub folder
ALT+ENTER
Wyświetlić właściwości wybranego elementu
ALT+F4
Zamknąć aktywny element lub zakończyć pracę z aktywnym programem
ALT+SPACJA
Otworzyć menu skrótów aktywnego okna
CTRL+F4
Zamknąć aktywny dokument (w programach, w których może być jednocześnie otwartych wielu dokumentów)
ALT+TAB
Przełączyć między otwartymi elementami
CTRL+ALT+TAB
Korzystając z klawiszy strzałek, przełączyć się między otwartymi elementami
Windows Klawisz logo +TAB
Przechodzić między kolejnymi programami na pasku zadań przy użyciu funkcji Flip 3-D systemu Windows
CTRL+klawisz logo Windows +TAB
Korzystając z klawiszy strzałek, przechodzić między kolejnymi programami na pasku zadań za pomocą funkcji Flip 3-D systemu Windows
ALT+ESC
Przechodzić między elementami w kolejności, w jakiej zostały otwarte
F6
Przechodzić między kolejnymi elementami okna lub pulpitu
F4
Wyświetlić listę paska adresu w Eksploratorze Windows
SHIFT+F10
Wyświetlić menu skrótów wybranego elementu
CTRL+ESC
Otworzyć menu Start
ALT+podkreślona litera
Wyświetlić odpowiednie menu
ALT+podkreślona litera
Wykonać polecenie menu (lub inne podkreślone polecenie)
F10
Uaktywnić pasek menu w aktywnym programie
STRZAŁKA W PRAWO
Otworzyć następne menu z prawej strony lub otworzyć podmenu
STRZAŁKA W LEWO
Otworzyć następne menu z lewej strony lub zamknąć podmenu
F5
Odświeżyć aktywne okno
ALT+STRZAŁKA W GÓRĘ
Wyświetlić folder znajdujący się o jeden poziom wyżej w Eksploratorze Windows
ESC
Anulować bieżące zadanie
CTRL+SHIFT+ESC
Otworzyć Menedżera zadań
SHIFT podczas wkładania dysku CD
Zapobiec automatycznemu odtwarzaniu dysku CD
Skróty klawiaturowe w oknach dialogowych:
CTRL+TAB
Przejść do następnej karty
CTRL+SHIFT+TAB
Przejść do poprzedniej karty
TAB
Przejść do następnej opcji
SHIFT+TAB
Przejść do poprzedniej opcji
ALT+podkreślona litera
Wykonać polecenie lub wybrać opcję skojarzoną z tą literą
ENTER
Zastępuje kliknięcie myszy w przypadku wielu wybranych poleceń.
SPACJA
Zaznaczyć lub wyczyścić pole wyboru, jeśli aktywna opcja jest polem wyboru
Klawisze strzałek
Zaznaczyć przycisk, jeśli aktywna opcja jest grupą przycisków opcji
F1
Wyświetlanie pomocy
F4
Wyświetlić elementy na aktywnej liście
BACKSPACE
Otworzyć folder znajdujący się o jeden poziom wyżej, jeśli w oknie dialogowym Zapisz jako lub Otwórz jest zaznaczony folder
Skróty klawiaturowe używane z klawiaturami firmy Microsoft:
Windows Klawisz logo
Otworzyć lub zamknąć menu Start
Windows Klawisz logo +PAUSE
Wyświetlić okno dialogowe Właściwości systemu
Windows Klawisz logo +D
Wyświetlić pulpit
Windows Klawisz logo +M
Zminimalizować wszystkie okna
Windows Klawisz logo +SHIFT+M
Przywrócić zminimalizowane okna na pulpit
Windows Klawisz logo +E
Otworzyć folder Komputer
Windows Klawisz logo +F
Wyszukać plik lub folder
CTRL+klawisz logo Windows +F
Wyszukać komputery (jeśli użytkownik pracuje w sieci)
Windows Klawisz logo +L
Zablokować komputer lub przełączyć użytkowników
Windows Klawisz logo +R
Otworzyć okno dialogowe Uruchamianie
Windows Klawisz logo +T
Przechodzić między programami na pasku zadań
Windows Klawisz logo +TAB
Przechodzić między kolejnymi programami na pasku zadań przy użyciu funkcji Flip 3-D systemu Windows
CTRL+klawisz logo Windows +TAB
Korzystając z klawiszy strzałek, przechodzić między kolejnymi programami na pasku zadań za pomocą funkcji Flip 3-D systemu Windows
Windows Klawisz logo +SPACJA
Wyświetlić wszystkie gadżety na pierwszym planie i wybrać pasek boczny systemu Windows
Windows Klawisz logo +G
Przechodzić między kolejnymi gadżetami na pasku bocznym
Windows Klawisz logo +U
Otworzyć Centrum ułatwień dostępu
Windows Klawisz logo +X
Otworzyć Centrum mobilności w systemie Windows
Windows Klawisz logo z dowolnym klawiszem numerycznym
Otworzyć skrót menu Szybkie uruchamianie, który znajduje się na pozycji odpowiadającej klawiszowi numerycznemu. Na przykład klawisz logo Windows +1, aby uruchomić pierwszy skrót w menu Szybkie uruchamianie.
Skróty klawiaturowe Eksploratora Windows:
CTRL+N
Otworzyć nowe okno
END
Wyświetlić dolną część aktywnego okna
HOME
Wyświetlić górną część aktywnego okna
F11
Zmaksymalizować lub zminimalizować aktywne okno
NUM LOCK+GWIAZDKA (*) na klawiaturze numerycznej
Wyświetlić wszystkie podfoldery w wybranym folderze
NUM LOCK+ZNAK PLUS (+) na klawiaturze numerycznej
Wyświetlić zawartość wybranego folderu
NUM LOCK+ZNAK MINUS (-) na klawiaturze numerycznej
Zwinąć wybrany folder
STRZAŁKA W LEWO
Zwinąć bieżące zaznaczenie (jeśli jest rozwinięte) lub wybrać folder nadrzędny
ALT+STRZAŁKA W LEWO
Wyświetlić poprzedni folder
STRZAŁKA W PRAWO
Wyświetlić bieżące zaznaczenie (jeśli jest zwinięte) lub wybrać pierwszy podfolder
ALT+STRZAŁKA W PRAWO
Wyświetlić następny folder
ALT+D
Wybrać pasek adresu
Skróty klawiaturowe paska bocznego systemu Windows:
Windows Klawisz logo +SPACJA
Wyświetlić wszystkie gadżety na pierwszym planie i wybrać pasek boczny
Windows Klawisz logo +G
Przechodzić między kolejnymi gadżetami na pasku bocznym
TAB
Przechodzić między kolejnymi formantami paska bocznego
Skróty klawiaturowe Galerii fotografii systemu Windows:
CTRL+F
Otworzyć okienko Napraw
CTRL+P
Wydrukować wybrany obraz
ENTER
Wyświetlić wybrany obraz w większej skali
CTRL+I
Otworzyć lub zamknąć okienko szczegółów
CTRL+KROPKA (.)
Obrócić obraz zgodnie z ruchem wskazówek zegara
CTRL+PRZECINEK (,)
Obrócić obraz zgodnie przeciwnie do ruchu wskazówek zegara
F2
Zmienić nazwę wybranego elementu
CTRL+E
Wyszukać element
ALT+STRZAŁKA W LEWO
Przejść wstecz
ALT+STRZAŁKA W PRAWO
Przejść do przodu
ZNAK PLUS (+)
Powiększyć lub zmienić rozmiar miniatury obrazu
ZNAK MINUS (-)
Pomniejszyć lub zmienić rozmiar miniatury obrazu
CTRL+B
Optymalnie dopasować
STRZAŁKA W LEWO
Wybrać poprzedni element
STRZAŁKA W DÓŁ
Wybrać następny element lub wiersz
STRZAŁKA W GÓRĘ
Poprzedni element (Sztaluga) lub wiersz (Miniatura)
PAGE UP
Poprzedni ekran
PAGE DOWN
Następny ekran
HOME
Wybrać pierwszy element
END
Wybrać ostatni element
DELETE
Przenieść wybrany element do Kosza
SHIFT+DELETE
Trwale usunąć wybrany element
STRZAŁKA W LEWO
Zwinąć węzeł
STRZAŁKA W PRAWO
Rozwinąć węzeł
Skróty klawiaturowe do pracy z filmami wideo:
J
Przejść do poprzedniej klatki
K
Wstrzymać odtwarzanie
L
Przejść do następnej klatki
I
Ustawić punkt początkowy przycięcia
O
Ustawić punkt końcowy przycięcia
M
Podzielić klip
HOME
Zatrzymać i przewinąć do tyłu aż do punktu początkowego przycięcia
ALT+STRZAŁKA W PRAWO
Przejść do następnej klatki
ALT+STRZAŁKA W LEWO
Przejść do poprzedniej klatki
CTRL+K
Zatrzymać odtwarzanie i przewinąć do tyłu
CTRL+P
Odtworzyć od bieżącego miejsca
HOME
Przejść do punktu początkowego przycięcia
END
Przejść do punktu końcowego przycięcia
PAGE UP
Przejść do najbliższego punktu podziału przed bieżącą lokalizacją
PAGE DOWN
Przejść do najbliższego punktu podziału za bieżącą lokalizacją
Skróty klawiaturowe Podglądu pomocy systemu Windows:
ALT+C
Wyświetlić spis treści
ALT+N
Wyświetlić menu Ustawienia połączenia
F10
Wyświetlić menu Opcje
ALT+STRZAŁKA W LEWO
Przejść wstecz do poprzedniego (przeglądanego już) tematu
ALT+STRZAŁKA W PRAWO
Przejść do przodu do następnego (przeglądanego już) tematu
ALT+A
Wyświetlić stronę pomocy technicznej
ALT+HOME
Wyświetlić stronę główną Pomocy i obsługi technicznej
HOME
Przejść do początku tematu
END
Przejść do końca tematu
CTRL+F
Wyszukać bieżący temat
CTRL+P
Wydrukować temat
F3
Przejść do pola wyszukiwania
środa, 26 listopada 2008
[PHP] Jak sprawdzić z jakiej przeglądarki i z jakiego systemu korzysta gość naszej strony
Możemy bardzo łatwo sprawdzić z jakiej przeglądarki i jakiego systemu korzysta osoba, która odwiedza naszą stronę. Aby to sprawdzić odczytamy zawartość zmiennej globalnej $_SERVER['HTTP_USER_AGENT']w której znajdują się interesujące nas informacje.
Najpierw za pomocą komendy strtolower() zamienimy wszystkie litery na małe aby łatwiej nam się wyszukiwało informacji o przeglądarce i systemie. Następnie za pomocą strpos() sprawdzamy czy interesujące nas wyrażenie znajdują się w $_SERVER['HTTP_USER_AGENT']. Możemy to zrobić np. tak:
Najpierw za pomocą komendy strtolower() zamienimy wszystkie litery na małe aby łatwiej nam się wyszukiwało informacji o przeglądarce i systemie. Następnie za pomocą strpos() sprawdzamy czy interesujące nas wyrażenie znajdują się w $_SERVER['HTTP_USER_AGENT']. Możemy to zrobić np. tak:
wtorek, 25 listopada 2008
[BASH] Skróty klawiszowe w Bashu
Skróty klawiszowe to coś co bardzo przyspiesza naszą pracę w konsoli i nie tylko. W Linuxie skróty klawiszowe są dobrze przystosowane po to aby ułatwić nam pracę jednak wiele osób o nich zapomina. Postaram się przypomnieć te najważniejsze:
Skróty z Ctrl:
Ctrl + a - Przejdź na początek linii. Przydatne w przypadku wpisania długiej linii i potrzeby edycji początku komendy.
Ctrl + b - Przesunięcie o jeden znak w lewo. Działa jak lewy kursor.
Ctrl + c - Przerwanie wykonywania obecnej komendy.
Ctrl + d - Usunięcie znaku na kursorze. Działa jak Delete.
Ctrl + e - Przejście na koniec linii.
Ctrl + f - Przesunięcie o jeden znak w prawo. Działa jak prawy kursor.
Ctrl + k - Usunięcie wszystkiego od kursora do końca linii.
Ctrl + l - Czyszczenie ekranu.Działa jak Clear.
Ctrl + r - Przeszukiwania historii wstecz po wpisanych znakach.
Ctrl + R - Przeszukiwania historii wstecz po wielu zdarzeniach.
Ctrl + u - Usunięcie wszystkiego od kursora do początku linii.
Ctrl + xx - Poruszanie się pomiędzy końcem linii a daną pozycją kursora.
Ctrl + z - Zawieś / zatrzymaj wykonywaną komendę.
Skróty z Alt:
Alt + < - Przesuń się do pierwszej linii w historii.
Alt + > - Przesuń się do ostatniej linii w historii.
Alt + ? - Wyświetl listę komend, listę plików. Działa jak 2xTab.
Alt + * - Wstawia do komendy wszystkie możliwe dopasowania.
Alt + / - Próbuje uzupełnić nazwę pliku lub komendy.
Alt + . - Wstawia ostatni argument poprzedniej komendy.
Alt + b - Cofnij się o jedno wyrażenie.
Alt + c - Zamień mała literę na dużą przy wybranym wyrazie.
Alt + d - Usuń cały wyraz.
Alt + f - Przejdź do przodu o jedno wyrażenie.
Alt + l - Zamień dużą literę na małą przy wybranym wyrazie.
Alt + n - Przeszukaj historię do przodu.
Alt + p - Przeszukaj historię do tyłu.
Alt + r - Odwołaj komendę.
Alt + t - Zamień kolejność wyrazów.
Alt + u - Zamień małe litery na duże.
Alt + back-space - Usuwaj do tyłu całymi wyrazami.
Skróty z Tabulatorem (2T oznacza wciśnięcie Tab 2 razy):
2T - Wszystkie dostępne komendy.
(wyrażenie)2T - Wszystkie dostępne komendy rozpoczynające się od (wyrażenie)
/2T - Wyświetlenie struktury systemu łącznie z plikami ukrytymi.
*2T - Wyświetlenie plików wybranego katalogu bez plików ukrytych.
~2T - Wyświetlenie wszystkich użytkowników z "/etc/passwd"
$2T - Wyświetlenie wszystkich zmiennych systemowych.
@2T - Wpisy z "/etc/hosts"
=2T - Zawartość katalogu. Działa jak ls lub dir.
Skróty z Ctrl:
Ctrl + a - Przejdź na początek linii. Przydatne w przypadku wpisania długiej linii i potrzeby edycji początku komendy.
Ctrl + b - Przesunięcie o jeden znak w lewo. Działa jak lewy kursor.
Ctrl + c - Przerwanie wykonywania obecnej komendy.
Ctrl + d - Usunięcie znaku na kursorze. Działa jak Delete.
Ctrl + e - Przejście na koniec linii.
Ctrl + f - Przesunięcie o jeden znak w prawo. Działa jak prawy kursor.
Ctrl + k - Usunięcie wszystkiego od kursora do końca linii.
Ctrl + l - Czyszczenie ekranu.Działa jak Clear.
Ctrl + r - Przeszukiwania historii wstecz po wpisanych znakach.
Ctrl + R - Przeszukiwania historii wstecz po wielu zdarzeniach.
Ctrl + u - Usunięcie wszystkiego od kursora do początku linii.
Ctrl + xx - Poruszanie się pomiędzy końcem linii a daną pozycją kursora.
Ctrl + z - Zawieś / zatrzymaj wykonywaną komendę.
Skróty z Alt:
Alt + < - Przesuń się do pierwszej linii w historii.
Alt + > - Przesuń się do ostatniej linii w historii.
Alt + ? - Wyświetl listę komend, listę plików. Działa jak 2xTab.
Alt + * - Wstawia do komendy wszystkie możliwe dopasowania.
Alt + / - Próbuje uzupełnić nazwę pliku lub komendy.
Alt + . - Wstawia ostatni argument poprzedniej komendy.
Alt + b - Cofnij się o jedno wyrażenie.
Alt + c - Zamień mała literę na dużą przy wybranym wyrazie.
Alt + d - Usuń cały wyraz.
Alt + f - Przejdź do przodu o jedno wyrażenie.
Alt + l - Zamień dużą literę na małą przy wybranym wyrazie.
Alt + n - Przeszukaj historię do przodu.
Alt + p - Przeszukaj historię do tyłu.
Alt + r - Odwołaj komendę.
Alt + t - Zamień kolejność wyrazów.
Alt + u - Zamień małe litery na duże.
Alt + back-space - Usuwaj do tyłu całymi wyrazami.
Skróty z Tabulatorem (2T oznacza wciśnięcie Tab 2 razy):
2T - Wszystkie dostępne komendy.
(wyrażenie)2T - Wszystkie dostępne komendy rozpoczynające się od (wyrażenie)
/2T - Wyświetlenie struktury systemu łącznie z plikami ukrytymi.
*2T - Wyświetlenie plików wybranego katalogu bez plików ukrytych.
~2T - Wyświetlenie wszystkich użytkowników z "/etc/passwd"
$2T - Wyświetlenie wszystkich zmiennych systemowych.
@2T - Wpisy z "/etc/hosts"
=2T - Zawartość katalogu. Działa jak ls lub dir.
środa, 19 listopada 2008
[PHP] Jak zablokować powtórne przetwarzanie formularzy przy odświeżaniu strony?
Bardzo częstym problemem na który natrafiają początkujący programiści PHP jest problem ponownego wysłania danych po odświeżaniu strony do której zostały przesłane dane z formularza HTML. Jeżeli nasz skrypt dodaje dane z formularza do bazy danych to po odświeżeniu strony zwyczajnie je doda jeszcze raz. Możemy ten problem bardzo łatwo rozwiązać za pomocą sesji oraz bardzo prostej funkcji PHP:
W powyższej funkcji generujemy 32-znakowy unikalny hash przemnażając czas razy losową liczbę uzyskując w ten sposób unikalny identyfikator, który przypiszemy do naszego wysłanego formularza.
Następnie w formularzu dodajemy następującą ukrytą linię:
Wywołuje ona naszą funkcję wysyłając w zmiennej hash nasz unikalny klucz.
A tak wygląda plik, który odbiera dane z formularza:
Jeżeli zmienna sesyjna adduser nie istnieje lub jest różna od przesłanej zmiennej hash z formularza to skrypt tworzy taką zmienną sesyjną i wykonuje wszystkie czynności jakie powinien zrobić po prawidłowym wysłaniu formularza. Jeżeli natomiast taka zmienna istnieje i jest równa zmienna hash z formularza tzn. że ten formularz był już wysłany.
W powyższej funkcji generujemy 32-znakowy unikalny hash przemnażając czas razy losową liczbę uzyskując w ten sposób unikalny identyfikator, który przypiszemy do naszego wysłanego formularza.
Następnie w formularzu dodajemy następującą ukrytą linię:
Wywołuje ona naszą funkcję wysyłając w zmiennej hash nasz unikalny klucz.
A tak wygląda plik, który odbiera dane z formularza:
Jeżeli zmienna sesyjna adduser nie istnieje lub jest różna od przesłanej zmiennej hash z formularza to skrypt tworzy taką zmienną sesyjną i wykonuje wszystkie czynności jakie powinien zrobić po prawidłowym wysłaniu formularza. Jeżeli natomiast taka zmienna istnieje i jest równa zmienna hash z formularza tzn. że ten formularz był już wysłany.
wtorek, 18 listopada 2008
Jak skopiować cały system pomiędzy dwoma komputerami?
Czasami zdarza się, że musimy zrobić klona naszego systemu na drugim komputerze. Możemy to zrobić w bardzo prosty sposób bez zapisywania danych na CD lub na innych urządzeniach przenośnych, po prostu przez sieć.
Oto co musisz zrobić po kolei:
1) Uruchamiasz na komputerze źródłowym oraz na komputerze docelowym jakąś dystrybucję LiveCD Linux, np. Ubuntu.
2) Na komputerze źródłowym montujesz partycje, która zawiera system, który chcesz skopiować, a następnie pakujesz i wysyłasz go następującymi poleceniami:
3) Na komputerze docelowym montujesz partycje na którą chcesz skopiować pliki i zaczynasz ją kopiować i rozpakowywać:
nc (netcat) - komenda która jest używana do połączeń TCP pomiędzy dwoma hostami.
pv (progress viewer) - komenda która jest używana do wyświetlania progresu transferu.
tar - jest używany do archiwizacji plików.
Oto co musisz zrobić po kolei:
1) Uruchamiasz na komputerze źródłowym oraz na komputerze docelowym jakąś dystrybucję LiveCD Linux, np. Ubuntu.
2) Na komputerze źródłowym montujesz partycje, która zawiera system, który chcesz skopiować, a następnie pakujesz i wysyłasz go następującymi poleceniami:
cd /mnt/sda1
tar -czpsf - . | pv -b | nc -l 3333
tar -czpsf - . | pv -b | nc -l 3333
3) Na komputerze docelowym montujesz partycje na którą chcesz skopiować pliki i zaczynasz ją kopiować i rozpakowywać:
cd /mnt/sda1
nc 192.168.10.101 3333 | pv -b | tar -xzpsf -
nc 192.168.10.101 3333 | pv -b | tar -xzpsf -
nc (netcat) - komenda która jest używana do połączeń TCP pomiędzy dwoma hostami.
pv (progress viewer) - komenda która jest używana do wyświetlania progresu transferu.
tar - jest używany do archiwizacji plików.
niedziela, 9 listopada 2008
Jak ściągnąć całą stronę www za pomocą wget
Dzisiaj trochę o małym wielkim programie do ściągania plików o nazwie wget, a właściwie o jego umiejętności ściągania całych stron internetowych bez mrugnięcia okiem.
Aby ściągnąć daną stronę www musimy wydać następującą komendę:
Dobrze, a teraz przeanalizujmy poszczególne wpisy:
--recursive - ściągaj całą stronę z podstronami.
--no-clobber - nie nadpisuj plików, które już istnieją (przydatne jeszcze wcześniej nie ściągnęliśmy całej strona a teraz chcemy kontynuować ściąganie).
--page-requisites - ściągaj wszystkie pliki związane ze stroną, czyli css, js, etc.
--html-extension - zapisuj pliki używając rozszerzenia html.
--convert-links - skonwertuj linki tak aby działały lokalnie, czyli off-line.
--restrict-file-names=windows - zmodyfikuj nazwy linków tak by działały również na windowsie.
--domains kursyonline.pl - ściągaj strony tylko z domeny kursyonline.pl. Nie podążaj za linkami zewnętrznymi.
--no-parent - nie podążaj za linkami z poza katalogu /kursy/php/.
Aby ściągnąć daną stronę www musimy wydać następującą komendę:
$ wget --recursive --no-clobber --page-requisites --html-extension --convert-links --restrict-file-names=windows --domains kursyonline.pl --no-parent www.kursyonline.pl/kursy/php
Dobrze, a teraz przeanalizujmy poszczególne wpisy:
--recursive - ściągaj całą stronę z podstronami.
--no-clobber - nie nadpisuj plików, które już istnieją (przydatne jeszcze wcześniej nie ściągnęliśmy całej strona a teraz chcemy kontynuować ściąganie).
--page-requisites - ściągaj wszystkie pliki związane ze stroną, czyli css, js, etc.
--html-extension - zapisuj pliki używając rozszerzenia html.
--convert-links - skonwertuj linki tak aby działały lokalnie, czyli off-line.
--restrict-file-names=windows - zmodyfikuj nazwy linków tak by działały również na windowsie.
--domains kursyonline.pl - ściągaj strony tylko z domeny kursyonline.pl. Nie podążaj za linkami zewnętrznymi.
--no-parent - nie podążaj za linkami z poza katalogu /kursy/php/.
czwartek, 6 listopada 2008
Video tutorial IPTABLES - linux firewall
Bardzo interesujący tutorial o budowie firewalla za pomocą IPTABLES. Zapraszam do oglądania!
Część 1
Część 2
Część 3
A poniżej gotowy firewall:
Część 1
Część 2
Część 3
A poniżej gotowy firewall:
1. #!/bin/sh
2.
3. IPT=/sbin/iptables
4.
5. $IPT -F
6.
7. #policies
8.
9. $IPT -P OUTPUT ACCEPT
10. $IPT -P INPUT DROP
11. $IPT -P FORWARD DROP
12. $IPT -t nat -P OUTPUT ACCEPT
13. $IPT -t nat -P PREROUTING ACCEPT
14. $IPT -t nat -P POSTROUTING ACCEPT
15.
16.
17.
18. $IPT -N SERVICES
19.
20. #drop spoofed packets
21.
22. $IPT -A INPUT --in-interface ! lo --source 127.0.0.0/8 -j DROP
23.
24. #limit ping requests
25.
26. $IPT -A INPUT -p icmp -m icmp -m limit --limit 1/second -j ACCEPT
27.
28. #drop bogus packets
29.
30. iptables -A INPUT -m state --state INVALID -j DROP
31. iptables -A FORWARD -m state --state INVALID -j DROP
32. iptables -A OUTPUT -m state --state INVALID -j DROP
33. $IPT -t filter -A INPUT -p tcp --tcp-flags FIN,ACK FIN -j DROP
34. $IPT -t filter -A INPUT -p tcp --tcp-flags ACK,PSH PSH -j DROP
35. $IPT -t filter -A INPUT -p tcp --tcp-flags ACK,URG URG -j DROP
36. $IPT -t filter -A INPUT -p tcp --tcp-flags SYN,FIN SYN,FIN -j DROP
37. $IPT -t filter -A INPUT -p tcp --tcp-flags SYN,RST SYN,RST -j DROP
38. $IPT -t filter -A INPUT -p tcp --tcp-flags FIN,RST FIN,RST -j DROP
39. $IPT -t filter -A INPUT -p tcp --tcp-flags ALL FIN,PSH,URG -j DROP
40.
41. #allowed inputs
42.
43. $IPT -A INPUT --in-interface lo -j ACCEPT
44. $IPT -A INPUT -j SERVICES
45.
46. #allow responses
47.
48. $IPT -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
49.
50.
51. #allow services
52.
53. $IPT -A SERVICES -p tcp --dport 22 -j ACCEPT
54. $IPT -A SERVICES -p tcp --dport 8080 -j ACCEPT
55.
56. $IPT -A SERVICES -m iprange --src-range 192.168.1.1-192.168.1.254 -p tcp --dport 631 -j ACCEPT
57.
58. $IPT -A SERVICES -m iprange --src-range 192.168.1.1-192.168.1.254 -p udp --dport 631 -j ACCEPT
59.
60.
61. $IPT -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
62.
63. $IPT -A FORWARD -p tcp --dport 8080 -j ACCEPT
2.
3. IPT=/sbin/iptables
4.
5. $IPT -F
6.
7. #policies
8.
9. $IPT -P OUTPUT ACCEPT
10. $IPT -P INPUT DROP
11. $IPT -P FORWARD DROP
12. $IPT -t nat -P OUTPUT ACCEPT
13. $IPT -t nat -P PREROUTING ACCEPT
14. $IPT -t nat -P POSTROUTING ACCEPT
15.
16.
17.
18. $IPT -N SERVICES
19.
20. #drop spoofed packets
21.
22. $IPT -A INPUT --in-interface ! lo --source 127.0.0.0/8 -j DROP
23.
24. #limit ping requests
25.
26. $IPT -A INPUT -p icmp -m icmp -m limit --limit 1/second -j ACCEPT
27.
28. #drop bogus packets
29.
30. iptables -A INPUT -m state --state INVALID -j DROP
31. iptables -A FORWARD -m state --state INVALID -j DROP
32. iptables -A OUTPUT -m state --state INVALID -j DROP
33. $IPT -t filter -A INPUT -p tcp --tcp-flags FIN,ACK FIN -j DROP
34. $IPT -t filter -A INPUT -p tcp --tcp-flags ACK,PSH PSH -j DROP
35. $IPT -t filter -A INPUT -p tcp --tcp-flags ACK,URG URG -j DROP
36. $IPT -t filter -A INPUT -p tcp --tcp-flags SYN,FIN SYN,FIN -j DROP
37. $IPT -t filter -A INPUT -p tcp --tcp-flags SYN,RST SYN,RST -j DROP
38. $IPT -t filter -A INPUT -p tcp --tcp-flags FIN,RST FIN,RST -j DROP
39. $IPT -t filter -A INPUT -p tcp --tcp-flags ALL FIN,PSH,URG -j DROP
40.
41. #allowed inputs
42.
43. $IPT -A INPUT --in-interface lo -j ACCEPT
44. $IPT -A INPUT -j SERVICES
45.
46. #allow responses
47.
48. $IPT -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
49.
50.
51. #allow services
52.
53. $IPT -A SERVICES -p tcp --dport 22 -j ACCEPT
54. $IPT -A SERVICES -p tcp --dport 8080 -j ACCEPT
55.
56. $IPT -A SERVICES -m iprange --src-range 192.168.1.1-192.168.1.254 -p tcp --dport 631 -j ACCEPT
57.
58. $IPT -A SERVICES -m iprange --src-range 192.168.1.1-192.168.1.254 -p udp --dport 631 -j ACCEPT
59.
60.
61. $IPT -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
62.
63. $IPT -A FORWARD -p tcp --dport 8080 -j ACCEPT
środa, 5 listopada 2008
Jak odmontować pendrive'a po informacji: umount: /media/usbdisk: device is busy...
Jeżeli chcesz odmontować dysk USB i otrzymasz informację w stylu:
spróbuj uzyć komendy lsof dzięki której możesz sprawdzić który program używa twojego pendrive'a:
Aby zobaczyć, który plik jest w użyciu wystarczy wpisać:
Teraz wystarczy tylko poczekać aż dany proces skończy działać lub wyłączyć go ręcznie podając PID:
# umount /media/usbdisk/
umount: /media/usbdisk: device is busy
umount: /media/usbdisk: device is busy
spróbuj uzyć komendy lsof dzięki której możesz sprawdzić który program używa twojego pendrive'a:
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
xmms 2567 wojtek cwd DIR 8,17 4096 1 /media/usbdisk/
xmms 2567 wojtek cwd DIR 8,17 4096 1 /media/usbdisk/
Aby zobaczyć, który plik jest w użyciu wystarczy wpisać:
# lsof /dev/sdb1
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
xmms 2567 wojtek cwd DIR 8,17 4096 1 /media/usbdisk
xmms 2567 wojtek 8r REG 8,17 2713101 377 /media/usbdisk/music.mp3
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
xmms 2567 wojtek cwd DIR 8,17 4096 1 /media/usbdisk
xmms 2567 wojtek 8r REG 8,17 2713101 377 /media/usbdisk/music.mp3
Teraz wystarczy tylko poczekać aż dany proces skończy działać lub wyłączyć go ręcznie podając PID:
# kill 2567
środa, 22 października 2008
Resetowanie zapomnianego hasła w MySQL
Czasami zdarza się nam zapomnieć hasła roota w mysql. Mi to się zdarzyło przynajmniej kilka razy na serwerach na których rzadko pracowałem. Na szczęście możliwe jest zresetowania hasła do mysql z poziomu systemowego użytkownika root.
Najpierw zatrzymujemy mysql:
/etc/init.d/mysql stop
Następnie:
mysqld –skip-grant-tables –u root
mysql -u root
mysql> use mysql;
mysql> UPDATE user SET Password = PASSWORD(’newpass’) WHERE User = ‘root’;
mysql> FLUSH PRIVILEGES;
I gotowe. Teraz nasze hasło do mysql to ’newpass’.
Najpierw zatrzymujemy mysql:
/etc/init.d/mysql stop
Następnie:
mysqld –skip-grant-tables –u root
mysql -u root
mysql> use mysql;
mysql> UPDATE user SET Password = PASSWORD(’newpass’) WHERE User = ‘root’;
mysql> FLUSH PRIVILEGES;
I gotowe. Teraz nasze hasło do mysql to ’newpass’.
piątek, 10 października 2008
Wprowadzenie do wyrażeń regularnych w PHP - metaznaki
Jeżeli często używamy linuxa to na pewno wyrażenia regularne nie są nam obce. Również wiele języków webowych ma dobrze rozwiniętą obsługę tych wyrażeń. Dzisiaj przyjrzymy się wykorzystywaniu wyrażeń regularnych (ang. regular expressions, w skrócie regex lub regexp) w PHP.
Wyrażenia regularne są potężną techniką opisywania wzorców tekstu występujących w plikach tekstowych - wiele programów wykorzystuje tą funkcjonalność. Programy do wyszukiwania takie jak 'grep' opierają się właśnie na tych wyrażeniach. Zasadniczo wyrażenia regularne ukształtowały się w świecie linuxa. Powstało wiele języków skryptowych, takich jak perl, ruby, PHP, JS, etc., które bazują na wyrażeniach regularnych. Wyrażenia regularne są również intensywnie wykorzystywane w module mod_rewrite w Apache'u, który opisałem we wcześniejszych postach. Coraz mniej jest języków, które nie posiadają choćby kilku funkcji wykorzystujących wyrażenia regularne, tak więc bardzo istotną sprawą jest opanowanie tego wielofunkcyjnego narzędzia.
Nie przestrasz się zewnętrznym wyglądem ułożonych wyrażeń regularnych; mnóstwo znaków specjalnych sprawia wrażenia trudnego do opanowania, ale jak już poznasz podstaw to uświadomisz sobie, że łatwiej już chyba nie może być. Przykładowo, za pomocą wzorca [a-zA-Z0-9._-]+@[a-zA-Z0-9-]+\.[a-zA-Z]{2,4} można sprawdzić poprawność wpisanego w formularz adresu e-mail. Poznając podstawy wyrażeń regularnych powyższy zapis stanie się dla Ciebie jasny jak słońce.
Metaznaki:
Wyrażenia regularne mogą składać się ze zwykłych znaków lub z metaznaków. Zwykłe znaki to np. zapis "RegEx is easy", natomiast metaznaki oprócz tego, że wyglądają jak zwykłe znaki, mają dodatkowo pewne zastosowanie merytoryczne. W wyrażeniach regularnych używając zwykłego znaku np. "P", znajdujemy w tekście "P". Jeżeli użyjemy metaznaku, możemy dopasować o wiele więcej szukanych fragmentów.
Wyróżniamy następujące metaznaki:
. + ? * ^ $ [ ( ) \ | {
Słownie te znaki to: kropka, plus, znak zapytania, asterisk, karetka, dolar, nawias kwadratowy otwierający, nawiasy zwykłe, backslash, kreska pionowa (alternatywa), klamra otwierająca.
Najłatwiej jest zrozumieć działanie metaznaków na przykładzie. Załóżmy, że chcemy w pliku tekstowym odnaleźć wszelkie wpisy o treści *.php to nasze wyrażenie regularne będzie miało postać \*\.php a nie *.php, ponieważ * i . to metaznaki i aby były traktowane jako normalny znak musimy użyć backslasha. Z angielskiego nazywa się to escape character, jednak trzeba pamiętać aby używać go tylko przed mataznakami, czyli przed '(', ')', '[', ']', '{', '}', '\', '*', '|', '^', '$', '?' przed zwykłymi znakami powoduje coś zupełnie innego, a mianowicie predefiniowane klasy znakowe. Ale o tym w kolejnym poście.
Wyrażenia regularne są potężną techniką opisywania wzorców tekstu występujących w plikach tekstowych - wiele programów wykorzystuje tą funkcjonalność. Programy do wyszukiwania takie jak 'grep' opierają się właśnie na tych wyrażeniach. Zasadniczo wyrażenia regularne ukształtowały się w świecie linuxa. Powstało wiele języków skryptowych, takich jak perl, ruby, PHP, JS, etc., które bazują na wyrażeniach regularnych. Wyrażenia regularne są również intensywnie wykorzystywane w module mod_rewrite w Apache'u, który opisałem we wcześniejszych postach. Coraz mniej jest języków, które nie posiadają choćby kilku funkcji wykorzystujących wyrażenia regularne, tak więc bardzo istotną sprawą jest opanowanie tego wielofunkcyjnego narzędzia.
Nie przestrasz się zewnętrznym wyglądem ułożonych wyrażeń regularnych; mnóstwo znaków specjalnych sprawia wrażenia trudnego do opanowania, ale jak już poznasz podstaw to uświadomisz sobie, że łatwiej już chyba nie może być. Przykładowo, za pomocą wzorca [a-zA-Z0-9._-]+@[a-zA-Z0-9-]+\.[a-zA-Z]{2,4} można sprawdzić poprawność wpisanego w formularz adresu e-mail. Poznając podstawy wyrażeń regularnych powyższy zapis stanie się dla Ciebie jasny jak słońce.
Metaznaki:
Wyrażenia regularne mogą składać się ze zwykłych znaków lub z metaznaków. Zwykłe znaki to np. zapis "RegEx is easy", natomiast metaznaki oprócz tego, że wyglądają jak zwykłe znaki, mają dodatkowo pewne zastosowanie merytoryczne. W wyrażeniach regularnych używając zwykłego znaku np. "P", znajdujemy w tekście "P". Jeżeli użyjemy metaznaku, możemy dopasować o wiele więcej szukanych fragmentów.
Wyróżniamy następujące metaznaki:
. + ? * ^ $ [ ( ) \ | {
Słownie te znaki to: kropka, plus, znak zapytania, asterisk, karetka, dolar, nawias kwadratowy otwierający, nawiasy zwykłe, backslash, kreska pionowa (alternatywa), klamra otwierająca.
. - kropka pasuje do dowolnego znaku, a więc wyrażenie r.d pasuje do wyrażeń rod, rad, rid, r$d, r6d, itd.
+ - plus to jedno lub więcej wystąpień wyrażenia poprzedzającego, np. Do+M pasuje do DoM, DooM, DoooM, DooooM, itd.
? - znak zapytania oznacza zero lub jedno wystąpienie poprzedzajacego wyrażenia, a więc np. Do?M pasuje do DM lub DoM.
* - asteriks to zero lub więcej wystąpień wyrażenia poprzedzającego, np. Do*M pasuje do DM, DoM, DooM, DoooM, DooooM, itd.
^ - karetka użyta na początku wyrażenia (przed nawiasami) odpowiada za początek linii, natomiast użyta po nawiasie kwadratowym oznacza zaprzeczenie, np. [^0-9] oznacza wszystkie znaki z wyjątkiem liczb od 0 do 9.
$ - dolar oznacza koniec danego napisu lub po prostu koniec linii
[ ] - nawiasy kwadratowe służą do dopasowywania liter z podanego zbioru, np. [dgj] pasuje do jednej z liter, d, g lub j. [a-z] oznacza wszystkie małe litery od a do z, jednak taki zakres nie obejmuje polskich znaków. Aby określić wszystkie znaki polskiego alfabetu musimy użyć wyrażenia [a-zA-ZąćęłńóśźżĄĆĘŁŃÓŚŹŻ]
( ) - tzw. atom - umożliwia zastosowanie alternatywy | (or) oraz na dopasowywanie powtarzających się fragmentów ciągów znaków. Przykładowo, do wyrażenia /^(abc)+$/ pasują ciągi "abc", "abcabc", "abcabcabc" itd.
\ - backslash pozwala nam na używanie specjalnych znaków we wzorcu, tak aby były również wyszukiwane a nie traktowane jako metaznak. Tzn. aby znaleźć plik.txt musimy użyć zapisu plik\.txt. Wyrażenie plik.txt potraktowałoby nam kropkę jako metaznak i znalazłoby również wyrażenia takie jak plikitxt, plik1txt, etc.
| - pionowa kreska (ang. pipeline)oznacza alternatywę. Inaczej mówiąc jest to operator logiczny 'OR'. Jeżeli np. napiszemy a|b|c oznacza to, że w danym wyrażeniu może wystąpić a lub b lub c.
+ - plus to jedno lub więcej wystąpień wyrażenia poprzedzającego, np. Do+M pasuje do DoM, DooM, DoooM, DooooM, itd.
? - znak zapytania oznacza zero lub jedno wystąpienie poprzedzajacego wyrażenia, a więc np. Do?M pasuje do DM lub DoM.
* - asteriks to zero lub więcej wystąpień wyrażenia poprzedzającego, np. Do*M pasuje do DM, DoM, DooM, DoooM, DooooM, itd.
^ - karetka użyta na początku wyrażenia (przed nawiasami) odpowiada za początek linii, natomiast użyta po nawiasie kwadratowym oznacza zaprzeczenie, np. [^0-9] oznacza wszystkie znaki z wyjątkiem liczb od 0 do 9.
$ - dolar oznacza koniec danego napisu lub po prostu koniec linii
[ ] - nawiasy kwadratowe służą do dopasowywania liter z podanego zbioru, np. [dgj] pasuje do jednej z liter, d, g lub j. [a-z] oznacza wszystkie małe litery od a do z, jednak taki zakres nie obejmuje polskich znaków. Aby określić wszystkie znaki polskiego alfabetu musimy użyć wyrażenia [a-zA-ZąćęłńóśźżĄĆĘŁŃÓŚŹŻ]
( ) - tzw. atom - umożliwia zastosowanie alternatywy | (or) oraz na dopasowywanie powtarzających się fragmentów ciągów znaków. Przykładowo, do wyrażenia /^(abc)+$/ pasują ciągi "abc", "abcabc", "abcabcabc" itd.
\ - backslash pozwala nam na używanie specjalnych znaków we wzorcu, tak aby były również wyszukiwane a nie traktowane jako metaznak. Tzn. aby znaleźć plik.txt musimy użyć zapisu plik\.txt. Wyrażenie plik.txt potraktowałoby nam kropkę jako metaznak i znalazłoby również wyrażenia takie jak plikitxt, plik1txt, etc.
| - pionowa kreska (ang. pipeline)oznacza alternatywę. Inaczej mówiąc jest to operator logiczny 'OR'. Jeżeli np. napiszemy a|b|c oznacza to, że w danym wyrażeniu może wystąpić a lub b lub c.
Najłatwiej jest zrozumieć działanie metaznaków na przykładzie. Załóżmy, że chcemy w pliku tekstowym odnaleźć wszelkie wpisy o treści *.php to nasze wyrażenie regularne będzie miało postać \*\.php a nie *.php, ponieważ * i . to metaznaki i aby były traktowane jako normalny znak musimy użyć backslasha. Z angielskiego nazywa się to escape character, jednak trzeba pamiętać aby używać go tylko przed mataznakami, czyli przed '(', ')', '[', ']', '{', '}', '\', '*', '|', '^', '$', '?' przed zwykłymi znakami powoduje coś zupełnie innego, a mianowicie predefiniowane klasy znakowe. Ale o tym w kolejnym poście.
piątek, 3 października 2008
Strutkura katalogów systemu Linux
Sposób w jaki Linux rozmieszcza swoje pliku na dysku jest kompletnie różny od tego stosowanego w Windowsie. Każdy z użytkowników Linuxa zapewne pamięta kiedy pierwszy raz wyświetlił zawartość swojej partycji linuksowej - jak wielkie było było zdziwienie a zarazem przerażenie na myśl o pracy z takim "drzewem" a raczej "lasem" plików. Obecnie użytkownicy którzy przechodzą na Linuxa mają już pewien zarys tego co mogą tam zobaczyć, jednak dobra znajomość katalogów systemu jest kluczem do opanowania Linuxa w stopniu średnio-przeciętnego użytkowania.
Ten artykuł jest wstępem do poznania struktury plików - zostanie tu opisany pierwszy poziom katalogów Linuksa. Cały artykuł ma na celu ułatwić początkowym użytkownikom tego systemu wybór odpowiednich katalogów do instalacji konkretnych programów.
Poniżej znajduję się przykładowa struktura katalogów dla RedHat Linux.
/
Katalog główny oznaczony jest w Linuxie symbolem "/" (slash) - określonym jest również słowem "root", które oznacza z angielskiego korzeń. Wszystkie katalogi wywodzą się od tego jednego. To w tym miejscu jest zainstalowana cała struktura plików. Przenosząc to na język Windowsa - "/" jest tym sam co "c:" w Windowsie. Linux nie uruchomi się bez zawartości "/". Usunięcie stąd plików jest tym samym co usunięcie zawartości folderu "c:/Windows" w Windowsie.
/bin
Folder /bin zawiera ważne programy systemowe, czyli pliki binarne (wykonywalne). Od tego właśnie wywodzi się nazwa - "bin" jest skrótem od "binary". To tutaj znajdują się najczęściej używane programy, takie jak: cat, less, grep, more, cp, mkdir, date, dmesg, etc...
/boot
Jak sama nazwa wskazuje, ten katalog jest odpowiedzialny za uruchomienie całego systemu oraz same jądro Linuxa. Gdyby nie jądro nie byłoby Linuxa. To ono odpowiada za wszystkie uruchomione procesy w systemie. Drugim krytycznym dla systemu programem znajdującym w katalogu boot jest bootloader, czyli program odpowiadający za zlokalizowane jądra i uruchomienie go.
/dev
"Dev" jest skrótem słowa "device", czyli urządzenie. W Linuxie każde urządzenie jest plikiem. Oznacza to, że dla każdego podłączonego urządzenia w systemie zostaje utworzony odpowiadający mu plik, za pomocą którego system komunikuje się z urządzeniem. Jeżeli system wykrywa dysk kojarzy go z plikiem np."/dev/sda". W tym przypadku /dev jest katalogiem a /sda plikiem odpowiadającym za dysk. Tutaj koniecznie trzeba powiedzieć o pliku /dev/null, który jest jakby czarną dziurą - śmietnikiem na bity, które do niego wpadają. Wykorzystujemy je gdy np. chcemy przekierować dane ze standardowego wyjścia (ekranu) do miejsca w którym dane nie będą ani zapisane ani wyświetlane, czyli do /dev/null. Jeżeli np. chcemy sformatować cały dysk twardy możemy to zrobić komendą: 'dd if=/dev/null of=/dev/sda'. Skopiuje to zawartość urządzenia /dev/null, czyli naszą próżnię, na dysk twardy - cała zawartość dysku zostanie skasowana.
/etc
Jeżeli lubisz konfigurować programy, ustawiać system pod własne wymagania i grzebać w ustawieniach to w tym katalogu będziesz spędzał najwięcej czasu. W /etc system przechowuje pliki konfiguracyjne wszystkich programów. Oczywiście programy pod Linuxem domyślnie są już dosyć rozsądnie skonfigurowane ale jeżeli je jeszcze bardziej zoptymalizować to wystarczy, że otworzysz do edycji odpowiedni tekstowy plik konfiguracyjny i edytujesz odpowiednie linie. Przeważnie pliki konfiguracyjne są opatrzone sensownymi komentarzami i gotowymi komendami, które wystarczy odhashować i gotowe. Wystarczy podstawowa znajomość języka angielskiego.
/lib
W tym katalogu znajdziemy skompilowane biblioteki niezbędne do uruchomienia systemu. Większość plików znajdujących się w tym katalogu ma rozszerzenie '.so' co oznacza 'shared object'. Te pliki są tak zbudowane aby mogły być wykorzystane przez programu różnego rodzaju. Dzięki temu nie musimy ściągać różnych programów po 300 mb, ale np. programy, które zajmują 50 mb i korzystają z tych samych plików '.so' co inne programy. W Windowsie takie pliki mają nazwę 'Dynamically Linked Libraries' powszechnie znano jako DLL. Jako przeciętny użytkownik prawdopodobnie nie będziesz musiał korzystać z plików, które znajdują się w katalogu /lib. Cały proces kojarzenia plików odbywa się automatycznie. Czasami jednak możesz spotkać się z błędem 'missing shared object'. Oznacza to, że program który instalujesz lub uruchamiasz wymaga obecności innego programu.
/lost+found
W tym katalogu znajdziesz pliki odnalezione podczas wykonywania testów dysku. Do czego to się może przydać? Jeżeli użytkownik nie zamknie systemu prawidłowo lub system dozna nagłego braku zasilania to w trakcie następnego wczytywania się systemu zostanie uruchomiony program skanujący, który sprawdzi czy wszystko jest w porządku i w razie potrzeby spróbuje naprawić błędy. Wszelkie pliki uszkodzone i naprawione są umieszcza w katalogu /lost+found aby użytkownik mógł je przejrzeć i podjąć decyzję co z nimi dalej zrobić.
/mnt
/media
Te dwa katalogi znajdujące się w głównym katalogu sytemu odpowiedzialne są za montowanie dysków, cd-romów, pendrive'ów oraz wszelkich urządzeń przenoszących dane. W zależności od dystrybucji Linuxa w katalogu /media montowane są nośniki wymienne jak pendrive, dyskietka, karty pamięci, czy napędy cdrom. Natomiast w /mnt montowane są dyski twarde. Wyjątkiem tutaj jest Ubuntu, gdzie dyski montowane są w katalogu /media. We wcześniejszych dystrybucjach Linuxa konieczne było montowanie nośników ręcznie, tzn. poprzez odpowiednie komendy. Obecnie, w większości dystrybucji nośniki montowane są automatycznie po podłączeniu. Oczywiście można takie ustawienia zmienić i montować ręcznie. To samo dotyczy miejsca montowania - /mnt i /media to tylko domyślna konfiguracja dla montowanych nośników. Tak naprawdę możesz zamontować dowolne urządzenie w jakimkolwiek katalogu na dysku, jeżeli oczywiście masz do niego dostęp. Jednak montowanie urządzeń w tych katalog znacznie ułatwia nam późniejsze poruszanie się po nich. Jeśli chodzi o katalog /media to jest on nową rzeczą w Linuxie. Kiedyś używało się tylko katalogu /mnt.
/opt
Tutaj możemy instalować oprogramowanie dodatkowe. W Linuxie, mówiąc o oprogramowaniu dodatkowym, mam na myśli takie, które nie jest dostępne w repezytorium i jest instalowane z paczek. Aby nie oddzielać programów instalowanych ręcznie od tych systemowych poprzez np.zmianę nazwy katalogów możemy je po prostu zainstalować w /opt. Różne dystrybucje różnie się ustosunkowują do tego katalogu. Jeżeli domyślnie instalujesz Apache' jego pliki konfiguracyjne znajdują się w /etc. Jeżeli zainstalujesz Apache'a w pakiecie LAMP, wszystkie pliki instalują się w katalogu /opt. Więc często w nowych dystrybucjach ten katalog jest po prostu wykorzystywany do przechowywania oprogramowania trzeciego.
/proc
W tym katalogu znajdują się wszelkie informacje odnośnie uruchomionych na twoim systemie procesów jak również o stanie komputera. Np. plik '/proc/cpuinfo' przechowuje dane na temat twojego procesora: prędkość, marka, taktowanie, etc. Znajdziesz tam również informację związane z systemem plików, ilością wolnej pamięci, miejsca, itd.
/sys
Od wersji jądra w wersji 2.6 znajdziemy tam interfejs zmiany parametrów jądra. Obecnie katalog /sys przejmuje funkcjonalność katalogu /proc.
/tmp
W tym katalogu, jak sama nazwa wskazuje, zapisywane są pliki tymczasowe. Znajdziesz tutaj pliki, które system musiał pobrać np. podczas surfowania po internecie lub instalacji jakiegoś programu. Większość plików z tego katalogu po zakończeniu danej operacji jest usuwana automatycznie, jednak warto co jakiś czas tam zajrzeć aby sprawdzić czy system nie generuje nam jakiegoś zbędnego śmietnika plików.
/usr
Gdybyś teraz użył komendy 'ls /usr/bin' prawdopodobnie byś zobaczył bardzo długą listę różnego rodzaju programu. Pewnie trochę to Cię dziwi bo przecież wszystkie pliki binarne miały być trzymane w katalogu /bin, więc skąd tego tutaj tyle? Dzieje się tak ponieważ Linux rozdziela wszystkie programy na te które są niezbędne do uruchomienia systemu oraz na te, które są używane "dla wygody" przez użytkownika, np. przeglądarki, odtwarzacze muzyki i filmów, programy graficzne, itd, itd... Porównując Linuxa z Windowsem możemy powiedzieć, że /usr jest dla Linuxa tym czym "c:/Program Files" dla Windowsa.
/var
Jeżeli na twoim systemie działają różnego rodzaju serwery pocztowe, www, ftp, ssh itp. to będziesz bardzo często korzystał z katalogu /var, ponieważ znajdują się tutaj logi systemowe. Cały katalog działa podobnie do /tmp, ponieważ pliki przechowywane tutaj są tymczasowe ale nie w tym samym sensie co te w /tmp. Pliki znajdujące się w katalogu /var nie są krytyczne dla uruchomienia żadnego programu, natomiast pomagają użytkownikowi diagnozować co dzieje się w tle jego systemu. Z jaką częstotliwością te pliki będą się kasowały oraz ile miejsca zajmowały zależy od nas. W katalogu /var/mail znajduje się nasza poczta; wszystkie wysłane i odebrane wiadomości, więc nie oszczędzajmy miejsca na ten katalog.
Mam nadzieję, że ten artykuł chociaż trochę przybliżył początkującym użytkownikom jak również tym, którzy już od jakiegoś czasu pracują na Linuxie, rozeznanie się w strukturze katalogów Linuxa. Oczywiście Linux zawiera jeszcze mnóstwo miejsc o których nie pisałem a które mogą być kluczem w rozwiązaniu pewnym problemów użytkownika lub administratora systemu. Jeżeli masz jakiś konkretny problem związany z tym postem pisz do mnie lub w komentarzu. Postaram się Ci pomóc!
Ten artykuł jest wstępem do poznania struktury plików - zostanie tu opisany pierwszy poziom katalogów Linuksa. Cały artykuł ma na celu ułatwić początkowym użytkownikom tego systemu wybór odpowiednich katalogów do instalacji konkretnych programów.
Poniżej znajduję się przykładowa struktura katalogów dla RedHat Linux.

/
Katalog główny oznaczony jest w Linuxie symbolem "/" (slash) - określonym jest również słowem "root", które oznacza z angielskiego korzeń. Wszystkie katalogi wywodzą się od tego jednego. To w tym miejscu jest zainstalowana cała struktura plików. Przenosząc to na język Windowsa - "/" jest tym sam co "c:" w Windowsie. Linux nie uruchomi się bez zawartości "/". Usunięcie stąd plików jest tym samym co usunięcie zawartości folderu "c:/Windows" w Windowsie.
/bin
Folder /bin zawiera ważne programy systemowe, czyli pliki binarne (wykonywalne). Od tego właśnie wywodzi się nazwa - "bin" jest skrótem od "binary". To tutaj znajdują się najczęściej używane programy, takie jak: cat, less, grep, more, cp, mkdir, date, dmesg, etc...
/boot
Jak sama nazwa wskazuje, ten katalog jest odpowiedzialny za uruchomienie całego systemu oraz same jądro Linuxa. Gdyby nie jądro nie byłoby Linuxa. To ono odpowiada za wszystkie uruchomione procesy w systemie. Drugim krytycznym dla systemu programem znajdującym w katalogu boot jest bootloader, czyli program odpowiadający za zlokalizowane jądra i uruchomienie go.
/dev
"Dev" jest skrótem słowa "device", czyli urządzenie. W Linuxie każde urządzenie jest plikiem. Oznacza to, że dla każdego podłączonego urządzenia w systemie zostaje utworzony odpowiadający mu plik, za pomocą którego system komunikuje się z urządzeniem. Jeżeli system wykrywa dysk kojarzy go z plikiem np."/dev/sda". W tym przypadku /dev jest katalogiem a /sda plikiem odpowiadającym za dysk. Tutaj koniecznie trzeba powiedzieć o pliku /dev/null, który jest jakby czarną dziurą - śmietnikiem na bity, które do niego wpadają. Wykorzystujemy je gdy np. chcemy przekierować dane ze standardowego wyjścia (ekranu) do miejsca w którym dane nie będą ani zapisane ani wyświetlane, czyli do /dev/null. Jeżeli np. chcemy sformatować cały dysk twardy możemy to zrobić komendą: 'dd if=/dev/null of=/dev/sda'. Skopiuje to zawartość urządzenia /dev/null, czyli naszą próżnię, na dysk twardy - cała zawartość dysku zostanie skasowana.
/etc
Jeżeli lubisz konfigurować programy, ustawiać system pod własne wymagania i grzebać w ustawieniach to w tym katalogu będziesz spędzał najwięcej czasu. W /etc system przechowuje pliki konfiguracyjne wszystkich programów. Oczywiście programy pod Linuxem domyślnie są już dosyć rozsądnie skonfigurowane ale jeżeli je jeszcze bardziej zoptymalizować to wystarczy, że otworzysz do edycji odpowiedni tekstowy plik konfiguracyjny i edytujesz odpowiednie linie. Przeważnie pliki konfiguracyjne są opatrzone sensownymi komentarzami i gotowymi komendami, które wystarczy odhashować i gotowe. Wystarczy podstawowa znajomość języka angielskiego.
/lib
W tym katalogu znajdziemy skompilowane biblioteki niezbędne do uruchomienia systemu. Większość plików znajdujących się w tym katalogu ma rozszerzenie '.so' co oznacza 'shared object'. Te pliki są tak zbudowane aby mogły być wykorzystane przez programu różnego rodzaju. Dzięki temu nie musimy ściągać różnych programów po 300 mb, ale np. programy, które zajmują 50 mb i korzystają z tych samych plików '.so' co inne programy. W Windowsie takie pliki mają nazwę 'Dynamically Linked Libraries' powszechnie znano jako DLL. Jako przeciętny użytkownik prawdopodobnie nie będziesz musiał korzystać z plików, które znajdują się w katalogu /lib. Cały proces kojarzenia plików odbywa się automatycznie. Czasami jednak możesz spotkać się z błędem 'missing shared object'. Oznacza to, że program który instalujesz lub uruchamiasz wymaga obecności innego programu.
/lost+found
W tym katalogu znajdziesz pliki odnalezione podczas wykonywania testów dysku. Do czego to się może przydać? Jeżeli użytkownik nie zamknie systemu prawidłowo lub system dozna nagłego braku zasilania to w trakcie następnego wczytywania się systemu zostanie uruchomiony program skanujący, który sprawdzi czy wszystko jest w porządku i w razie potrzeby spróbuje naprawić błędy. Wszelkie pliki uszkodzone i naprawione są umieszcza w katalogu /lost+found aby użytkownik mógł je przejrzeć i podjąć decyzję co z nimi dalej zrobić.
/mnt
/media
Te dwa katalogi znajdujące się w głównym katalogu sytemu odpowiedzialne są za montowanie dysków, cd-romów, pendrive'ów oraz wszelkich urządzeń przenoszących dane. W zależności od dystrybucji Linuxa w katalogu /media montowane są nośniki wymienne jak pendrive, dyskietka, karty pamięci, czy napędy cdrom. Natomiast w /mnt montowane są dyski twarde. Wyjątkiem tutaj jest Ubuntu, gdzie dyski montowane są w katalogu /media. We wcześniejszych dystrybucjach Linuxa konieczne było montowanie nośników ręcznie, tzn. poprzez odpowiednie komendy. Obecnie, w większości dystrybucji nośniki montowane są automatycznie po podłączeniu. Oczywiście można takie ustawienia zmienić i montować ręcznie. To samo dotyczy miejsca montowania - /mnt i /media to tylko domyślna konfiguracja dla montowanych nośników. Tak naprawdę możesz zamontować dowolne urządzenie w jakimkolwiek katalogu na dysku, jeżeli oczywiście masz do niego dostęp. Jednak montowanie urządzeń w tych katalog znacznie ułatwia nam późniejsze poruszanie się po nich. Jeśli chodzi o katalog /media to jest on nową rzeczą w Linuxie. Kiedyś używało się tylko katalogu /mnt.
/opt
Tutaj możemy instalować oprogramowanie dodatkowe. W Linuxie, mówiąc o oprogramowaniu dodatkowym, mam na myśli takie, które nie jest dostępne w repezytorium i jest instalowane z paczek. Aby nie oddzielać programów instalowanych ręcznie od tych systemowych poprzez np.zmianę nazwy katalogów możemy je po prostu zainstalować w /opt. Różne dystrybucje różnie się ustosunkowują do tego katalogu. Jeżeli domyślnie instalujesz Apache' jego pliki konfiguracyjne znajdują się w /etc. Jeżeli zainstalujesz Apache'a w pakiecie LAMP, wszystkie pliki instalują się w katalogu /opt. Więc często w nowych dystrybucjach ten katalog jest po prostu wykorzystywany do przechowywania oprogramowania trzeciego.
/proc
W tym katalogu znajdują się wszelkie informacje odnośnie uruchomionych na twoim systemie procesów jak również o stanie komputera. Np. plik '/proc/cpuinfo' przechowuje dane na temat twojego procesora: prędkość, marka, taktowanie, etc. Znajdziesz tam również informację związane z systemem plików, ilością wolnej pamięci, miejsca, itd.
/sys
Od wersji jądra w wersji 2.6 znajdziemy tam interfejs zmiany parametrów jądra. Obecnie katalog /sys przejmuje funkcjonalność katalogu /proc.
/tmp
W tym katalogu, jak sama nazwa wskazuje, zapisywane są pliki tymczasowe. Znajdziesz tutaj pliki, które system musiał pobrać np. podczas surfowania po internecie lub instalacji jakiegoś programu. Większość plików z tego katalogu po zakończeniu danej operacji jest usuwana automatycznie, jednak warto co jakiś czas tam zajrzeć aby sprawdzić czy system nie generuje nam jakiegoś zbędnego śmietnika plików.
/usr
Gdybyś teraz użył komendy 'ls /usr/bin' prawdopodobnie byś zobaczył bardzo długą listę różnego rodzaju programu. Pewnie trochę to Cię dziwi bo przecież wszystkie pliki binarne miały być trzymane w katalogu /bin, więc skąd tego tutaj tyle? Dzieje się tak ponieważ Linux rozdziela wszystkie programy na te które są niezbędne do uruchomienia systemu oraz na te, które są używane "dla wygody" przez użytkownika, np. przeglądarki, odtwarzacze muzyki i filmów, programy graficzne, itd, itd... Porównując Linuxa z Windowsem możemy powiedzieć, że /usr jest dla Linuxa tym czym "c:/Program Files" dla Windowsa.
/var
Jeżeli na twoim systemie działają różnego rodzaju serwery pocztowe, www, ftp, ssh itp. to będziesz bardzo często korzystał z katalogu /var, ponieważ znajdują się tutaj logi systemowe. Cały katalog działa podobnie do /tmp, ponieważ pliki przechowywane tutaj są tymczasowe ale nie w tym samym sensie co te w /tmp. Pliki znajdujące się w katalogu /var nie są krytyczne dla uruchomienia żadnego programu, natomiast pomagają użytkownikowi diagnozować co dzieje się w tle jego systemu. Z jaką częstotliwością te pliki będą się kasowały oraz ile miejsca zajmowały zależy od nas. W katalogu /var/mail znajduje się nasza poczta; wszystkie wysłane i odebrane wiadomości, więc nie oszczędzajmy miejsca na ten katalog.
Mam nadzieję, że ten artykuł chociaż trochę przybliżył początkującym użytkownikom jak również tym, którzy już od jakiegoś czasu pracują na Linuxie, rozeznanie się w strukturze katalogów Linuxa. Oczywiście Linux zawiera jeszcze mnóstwo miejsc o których nie pisałem a które mogą być kluczem w rozwiązaniu pewnym problemów użytkownika lub administratora systemu. Jeżeli masz jakiś konkretny problem związany z tym postem pisz do mnie lub w komentarzu. Postaram się Ci pomóc!
sobota, 27 września 2008
Linux na PlayStation 3
Zapewne nie każdy wie, że na ostatniej konsoli wyprodukowanej przez sony można uruchomić system operacyjny, a mianowicie Linux. Taka funkcjonalność co prawda nie jest nowa, ale po raz pierwszy jest to standardowa możliwość, bez dodatkowych modyfikacji oraz rozszerzeń. Do tej pory konsole były tak konstruowane aby zapobiegać uruchomieniu obcych systemów a tym bardziej systemów darmowych. Inną konsolą na której jest to możliwe jest Xbox, jednak tutaj konieczne jest zainstalowanie dodatkowo chipa, więc wyraźnie widać kto tutaj zrobił zdecydowany krok naprzód.
Dzięki możliwości uruchomienia na PS3 systemu Linux mamy naprawdę duże możliwości konfiguracji. Jeżeli wspomnę, że jest możliwość podłączenia do konsoli klawiatury i myszy mamy do czynienia z przenośnym pecetem, na którym pójdą zaawansowane gry (te pod PSX). Jedyna rzecz, której nie uruchomimy na konsolowym systemie to akceleratory graficzne, ale patrząc na możliwość samej konsoli jeśli chodzi o gry to na pewno możemy sobie bez tego poradzić. Teraz możemy używać konsoli do surfowania po internecie, pracy w oprogramowaniu biurowym, uruchamiać wszelkie rodzaje formatów audio i video oraz udostępniać pliki w sieci!
Zalety linuxa znamy świetnie, ale znamy też jego rzekome wady, do których można zaliczyć trudny proces instalacji i konfiguracji na PS3. Dystrybucje linuxa dopiero zaczynają się dostosowywać do możliwości ich adaptacji na konsoli. Jak na razie ludzie którzy posiadają linuxa na swojej konsoli to są w głównej mierze hobbyści, którzy z linuxem są za pan brat od wielu lat i instalacja na flashdiskach nie sprawia im żadnego problemu. Ale pojawiło się światełko w tunelu dla ludzi, którzy znają linuxa albo ze słyszenia albo z pobieżnej pracy w graficznym środowisku. Pojawiła się dystrybucja Yellow Dog, która jest przeznaczona dla komputerów z procesorem PowerPC (np. komputery Amiga, wcześniejsze modele Apple Macintosh z procesorami Motorola oraz PlayStatin 3). Bazuje ona na dystrybucji Red Hat Linux i wydaję się, że wyjątkowo dobrze się rozwija.
Jak widać o linuxie w Świecie coraz głośniej; coraz więcej ludzi i organizacji docenia zalety tego w pełni konfigurowalnego systemu, więc osobiście uważam, ze czas poświęcony na nauczanie oraz samą pracę w tym systemie nigdy nie będzie czasem straconym.
Dzięki możliwości uruchomienia na PS3 systemu Linux mamy naprawdę duże możliwości konfiguracji. Jeżeli wspomnę, że jest możliwość podłączenia do konsoli klawiatury i myszy mamy do czynienia z przenośnym pecetem, na którym pójdą zaawansowane gry (te pod PSX). Jedyna rzecz, której nie uruchomimy na konsolowym systemie to akceleratory graficzne, ale patrząc na możliwość samej konsoli jeśli chodzi o gry to na pewno możemy sobie bez tego poradzić. Teraz możemy używać konsoli do surfowania po internecie, pracy w oprogramowaniu biurowym, uruchamiać wszelkie rodzaje formatów audio i video oraz udostępniać pliki w sieci!
Zalety linuxa znamy świetnie, ale znamy też jego rzekome wady, do których można zaliczyć trudny proces instalacji i konfiguracji na PS3. Dystrybucje linuxa dopiero zaczynają się dostosowywać do możliwości ich adaptacji na konsoli. Jak na razie ludzie którzy posiadają linuxa na swojej konsoli to są w głównej mierze hobbyści, którzy z linuxem są za pan brat od wielu lat i instalacja na flashdiskach nie sprawia im żadnego problemu. Ale pojawiło się światełko w tunelu dla ludzi, którzy znają linuxa albo ze słyszenia albo z pobieżnej pracy w graficznym środowisku. Pojawiła się dystrybucja Yellow Dog, która jest przeznaczona dla komputerów z procesorem PowerPC (np. komputery Amiga, wcześniejsze modele Apple Macintosh z procesorami Motorola oraz PlayStatin 3). Bazuje ona na dystrybucji Red Hat Linux i wydaję się, że wyjątkowo dobrze się rozwija.
Jak widać o linuxie w Świecie coraz głośniej; coraz więcej ludzi i organizacji docenia zalety tego w pełni konfigurowalnego systemu, więc osobiście uważam, ze czas poświęcony na nauczanie oraz samą pracę w tym systemie nigdy nie będzie czasem straconym.
środa, 24 września 2008
Jak wyłączyć irytujący dzwięk "beep" w VMware
Jak w tytule, niby proste ale nie do końca. Od jakiegoś czasu moje lenistwo wzięło górę na pisaniem postów na blogu dlatego powoli przerzucam się na screencasty. Wszelkie czynności związane zwłaszcza z linuxem będę przedstawiał na wirtualnych systemach, prawdopodobnie VMware. W tej chwili jestem w fazie testów i pewien problem przysporzyło mi wyłączenie irytującego dźwięku, który wydaję VMware jeżeli wykonamy w konsoli nieprawidłową operację np. usuwając jakiś tekst linii klawiszem backspace i w momencie skasowanie całego tekstu gdy dalej naciskamy backspace. Wydaję to się nie dużym problemem ale przy nagrywaniu screencastów znacznie obniża jakość nagrania. Wbrew temu co większość myśli sprawa wygląda trochę bardziej skomplikowanie niż tylko wejście w ustawienia i odhaczeniu checkboxa sound. Po kolei napiszę jak to zrobić w trzech najbardziej popularnych systemach operacyjnych.
1. Microsoft Vista
Cała sprawa wyłączenia tego dźwięku sprowadza się do odnalezienia pliku konfiguracyjnego VMware config.ini i wpisaniu tam linii:
mks.noBeep = "TRUE"
Problemem jest odnalezienie tego pliku o ile w ogóle istnieje. Vista przetrzymuje ten plik w katalogu ProgramData/VMware/VMware Workstation. Jeżeli tam go nie znajdziemy to znaczy, że nie edytowaliśmy żadnych ustawień w VMware i należy to zrobić poprzez edycja jakichś ustawień w programie, np. przez zmianę przydzielonej pamięci do hosta. Taka czynność powinna spowodować utworzenie takiego pliku. Jeżeli i to nie pomogło to należy taki plik utworzyć ręcznie w podanym katalogu. Przy edycji konieczne jest otworzenie tego pliku jako administrator.
2. Microsoft XP
Analogicznie jak powyżej tyle że w katalogu C:\Users\All Users\VMware\VMware Workstation\config.ini.
3. Linux
W tym miejscu linux nie różni się od powyższych systemów. katalog to: ~/.vmware/config.
W przypadku gdyby dźwięk ciągle się wydobywał piszcie w komentarzach.
1. Microsoft Vista
Cała sprawa wyłączenia tego dźwięku sprowadza się do odnalezienia pliku konfiguracyjnego VMware config.ini i wpisaniu tam linii:
mks.noBeep = "TRUE"
Problemem jest odnalezienie tego pliku o ile w ogóle istnieje. Vista przetrzymuje ten plik w katalogu ProgramData/VMware/VMware Workstation. Jeżeli tam go nie znajdziemy to znaczy, że nie edytowaliśmy żadnych ustawień w VMware i należy to zrobić poprzez edycja jakichś ustawień w programie, np. przez zmianę przydzielonej pamięci do hosta. Taka czynność powinna spowodować utworzenie takiego pliku. Jeżeli i to nie pomogło to należy taki plik utworzyć ręcznie w podanym katalogu. Przy edycji konieczne jest otworzenie tego pliku jako administrator.
2. Microsoft XP
Analogicznie jak powyżej tyle że w katalogu C:\Users\All Users\VMware\VMware Workstation\config.ini.
3. Linux
W tym miejscu linux nie różni się od powyższych systemów. katalog to: ~/.vmware/config.
W przypadku gdyby dźwięk ciągle się wydobywał piszcie w komentarzach.
środa, 27 sierpnia 2008
EA Sports kontra użytkownicy TouTube
Dzisiaj trochę z innej beczki ale ciągle o programowaniu ;) Jak wiadomo napisanie bezbłędnego programu nie jest rzeczą łatwą, zwłaszcza jeśli chodzi o grę komputerową. Tylko programiści gier mogą wiedzieć jak wiele warunków musi zostać spełnionych i ile testów musi przejść program zanim zostanie ostatecznie skończona - a terminy gonią. Dotyczy to w szczególności gier, które ukazują się co roku, odświeżone, z nazwą różniącą się tylko rokiem na końcu. Wiecie już o jakie gry chodzi? Oczywiście, słynne gry sportowo-zręcznościowe EA Sports. Bezwzględni użytkownicy YouTube nie przepuszczą żadnej grze, jeżeli zauważą jakieś bugi, publikując błędy w postaci filmów w internecie. Wchodząc na YouTube możecie znaleźć mnóstwo tego typu filmów, wystarczy wpisać "game bugs" lub coś podobnego. Do tej pory nikt z tego powodu nie był specjalnie urażony; twórcy gier uczyli się na błędach a internauci się śmiali. Levinator25 myślał, że tak będzie również tym razem i zamieścił na YouTubie filmik z bug'iem z Tiger Woods PGA Tour 08, w którym mogliśmy zobaczyć jak nasza postać w grze cudownie chodzi po wodzie. Chciałbym zobaczyć minę Levinatora25, kiedy zobaczył odpowiedź EA Sports na jego film ;) Obejrzyjmy ją razem.
niedziela, 24 sierpnia 2008
Google i matematyka
Właśnie trafiłem na pewną ciekawostkę. Nasza ulubiona wyszukiwarka nie jest jednak idealna - wystarczy wejść na google.pl i sprawdzić ile to jest 399 999 999 999 999-399 999 999 999 998. My znamy wynik, ale czy google zna? A może to kolejny żart jego twórców, obdarzonych tak dobrze już znanym i nie do końca rozumianym poczuciem humoru?
niedziela, 17 sierpnia 2008
Podstawy HTML i CSS - wideo tutorial
Serfując w sieci znalazłem bardzo interesujący tutorial - można się z niego w 40 minut nauczyć podstaw HTML i kilka naprawdę istotnych rzeczy na temat CSS. Jeżeli ktoś zaczyna zabawę z tymi językami to naprawdę gorąco polecam zacząć od tego - to tylko 40 minut!
źródło: http://pl.youtube.com/watch?v=GwQMnpUsj8I&feature=rec-fresh
źródło: http://pl.youtube.com/watch?v=GwQMnpUsj8I&feature=rec-fresh
piątek, 15 sierpnia 2008
Mod_rewrite, czyli przyjazne adresy URL z .htaccess
Często zdarza się, że nasze adresy URL do podstron zaczynają nabierać naprawdę przerażająco długiej długości, np. /index.php?id=galeria&sid=2008&ssid=wakacje. Z takim adresami często nie radzą sobie roboty indeksujące strony, dlatego część podstron może po prostu zostać nie dodana do indeksu. Oczywistym minusem tak długich adresów jest również ich nieczytelność. Tutaj z pomocą przychodzi nam moduł Apache'a - mod_rewrite. Przede wszystkim należy sprawdzić w pliku konfiguracyjnym Apache'a czy nasz serwer go obsługuje, szukamy więc linijki LoadModule rewrite_module modules/mod_rewrite.so. Jeżeli jest odhashowana to wszystko w porządku, w przeciwnym wypadku usuwamy hasha (#). Jeżeli oczywiście nie masz dostępu do pliku konfiguracyjnego to po prostu wykonaj w jakimś skrypcie php polecenie phpinfo(); i odszukaj części odpowiadającej za uruchomione moduły - powinieneś tam znaleźć wpis odpowiedzialny za mod_rewrite. Jeżeli go nie znajdziesz to musisz się skontaktować z administratorem w celu uruchomienia tego modułu.
Mod_rewrite korzysta z wyrażeń regularnych, oto najważniejsze z nich:
Przykładowy wpis do .htaccess może wyglądać tak:
Pierwsza linia powoduje uruchomienie mod-rewrite, natomiast w drugiej widzimy już użycie wyrażeń regularnych. Taki zapis oznacza, że jeżeli na serwerze mamy plik index.php to możemy się również do niego odnieść wpisując index.html. Jeżeli chodzi o atrybut [L] to jest to skrót od Last rule i oznacza on, że linia w której się znajduję jest ostatnią linią, czyli kolejne reguły nie będą dalej wykonywane. Dodatkowo możemy dopisać atrybut [NC], który oznacza że to czy adres będzie wpisany dużymi literami czy małymi nie robi żadnego znaczenia, tak więc wpisując
Teraz zajmijmy się już konkretnymi przykładami. Załóżmy, że nasza strona znajduję się pod takim adresem:
Tutaj bardziej czytelny przykład:
Zamieni on adres http://moja-strona.pl/wyswietl.php?what=aktualnosci&skad=kraj&id=108 na: http://moja-strona.pl/aktualnosci/kraj/108. Po więcej szczegółów odsyłam do dokumentacji Apachea.
Mod_rewrite korzysta z wyrażeń regularnych, oto najważniejsze z nich:
. Dowolny znak
^ Oznacza początek napisu
$ Oznacznik końca (c$ znaczy, że ciąg tekstowy musi zakończyć się na c)
+ Wystąpi jeden lub więcej razy
* Zero lub więcej wystąpień
? Zero lub jedno wystąpienie
! Negacja wyrażenia
( Rozpoczyna grupowanie (przetwarzanie ciągu znaków, jakby był to pojedynczy element)
[ Rozpoczyna klasę znaków, np. dopasowane do przedziału od 0 do 9, to definicja klasy [0-9]
^ Oznacza początek napisu
$ Oznacznik końca (c$ znaczy, że ciąg tekstowy musi zakończyć się na c)
+ Wystąpi jeden lub więcej razy
* Zero lub więcej wystąpień
? Zero lub jedno wystąpienie
! Negacja wyrażenia
( Rozpoczyna grupowanie (przetwarzanie ciągu znaków, jakby był to pojedynczy element)
[ Rozpoczyna klasę znaków, np. dopasowane do przedziału od 0 do 9, to definicja klasy [0-9]
Przykładowy wpis do .htaccess może wyglądać tak:
RewriteEngine on
RewriteRule ^index.html$ index.php [L]
RewriteRule ^index.html$ index.php [L]
Pierwsza linia powoduje uruchomienie mod-rewrite, natomiast w drugiej widzimy już użycie wyrażeń regularnych. Taki zapis oznacza, że jeżeli na serwerze mamy plik index.php to możemy się również do niego odnieść wpisując index.html. Jeżeli chodzi o atrybut [L] to jest to skrót od Last rule i oznacza on, że linia w której się znajduję jest ostatnią linią, czyli kolejne reguły nie będą dalej wykonywane. Dodatkowo możemy dopisać atrybut [NC], który oznacza że to czy adres będzie wpisany dużymi literami czy małymi nie robi żadnego znaczenia, tak więc wpisując
domeda.com/STRONA1/index.php otrzymamy to samo co przy wpisie domeda.com/strona1/index.php.Teraz zajmijmy się już konkretnymi przykładami. Załóżmy, że nasza strona znajduję się pod takim adresem:
www.strona.pl/menu.php?id=4. Aby adres był czytelny dla użytkownika dobrze jakby był takiego formatu: www.strona.pl/menu-4. Aby otrzymać taki wynik wystarczy dodać do .htaccess następującą linkijkę: RewriteRule ^menu-([^-]+).html$ menu.php?id=$1. Teraz po kolei wyjaśnię ten zapis: ([^-]+) oznacza wszystkie znaki z wyjątkiem myślnika, w takim przypadku za wykluczenie odpowiedzialny jest znak ^, natomiast + oznacza wystąpienie znaku raz lub więcej razy. Jeżeli np. chcemy aby tam były umieszczone wyłącznie liczby to wpisujemy ([0-9]+) . Jeśli chodzi o okrągłe nawiasy oznaczają one zmienne - w tym przypadku to co jest w nawiasie w pierwszej części ciągu jest przenoszone do drugiej części do zmiennej $1 i wyświetlane w URL. Jeżeli nawiasów byłoby więcej to odpowiadałyby one kolejno zmiennym $1 $2 $3 itd.Tutaj bardziej czytelny przykład:
RewriteEngine On
RewriteRule (aktualnosci)/(kraj)/([0-9]+) /wyswietl.php?what=$1&skad=$2&id=$3
#lub
RewriteRule (+)/(+)/([0-9]+) /wyswietl.php?what=$1&skad=$2&id=$3
#lub
RewriteRule ([a-z]+)/([a-z]+)/([0-9]+) /wyswietl.php?what=$1&skad=$2&id=$3
RewriteRule (aktualnosci)/(kraj)/([0-9]+) /wyswietl.php?what=$1&skad=$2&id=$3
#lub
RewriteRule (+)/(+)/([0-9]+) /wyswietl.php?what=$1&skad=$2&id=$3
#lub
RewriteRule ([a-z]+)/([a-z]+)/([0-9]+) /wyswietl.php?what=$1&skad=$2&id=$3
Zamieni on adres http://moja-strona.pl/wyswietl.php?what=aktualnosci&skad=kraj&id=108 na: http://moja-strona.pl/aktualnosci/kraj/108. Po więcej szczegółów odsyłam do dokumentacji Apachea.
.htaccess i blokowanie dostępu do stron
Wcześniej pisałem o blokowaniu dostępu do strony za pomocą pliku .htpasswd, jednak możemy również zablokować dostęp do naszych stron przez określony adres IP lub przez całe ich grupy. Tutaj jak zwykle przydatność takiego blokowania jest jedynie ograniczona przez naszą wyobraźnię. Adresy blokujemy komendą deny, np.:
Jeżeli chcemy ograniczyć dostęp wszystkim np. do jakiejś strony:
Istnieje również możliwość udostępnienia stron tylko wybranym adresom:
Często bardzo ważne jest nadanie kolejności przetwarzania wpisów, do tego celu używamy
Mamy również możliwość blokowania hostów z jakiejś określonej domeny. Robimy to tak samo jak powyżej, jednak zamiast adresu IP wpisujemy adres domeny, np.:
deny from 111.222.333.444
Jeżeli chcemy ograniczyć dostęp wszystkim np. do jakiejś strony:
deny from all
Istnieje również możliwość udostępnienia stron tylko wybranym adresom:
deny from all
allow from 111.222.333.444
W pierwszej linii blokujemy dostęp wszystkim adresom, a w drugiej linii dajemy dostęp określonym adresom IP.allow from 111.222.333.444
Często bardzo ważne jest nadanie kolejności przetwarzania wpisów, do tego celu używamy
Order allow, deny. Taki zapis powoduje, ze najpierw przetwarzane są instrukcje odpowiedzialne za dostęp a następnie te za blokowanie. Rozważmy następujący przykład:order allow, deny
deny from 111.222.333.444
deny from 555.666.777.888
allow from all
Jeżeli w takim przypadku nie użylibyśmy dyrektywy deny from 111.222.333.444
deny from 555.666.777.888
allow from all
order allow, deny to najpierw zostały by zablokowane adresy 111.222.333.444 i 555.666.777.888 po to tylko żeby za chwilę zostały odblokowane dyrektywą allow from all.Mamy również możliwość blokowania hostów z jakiejś określonej domeny. Robimy to tak samo jak powyżej, jednak zamiast adresu IP wpisujemy adres domeny, np.:
deny jakas.domena.com.
niedziela, 10 sierpnia 2008
Budowa stron błędów w .htaccess
Kontynuując tworzenie pliku .htacces napiszę trochę istotnych informacji na temat stron błędów a Apache. Za pomocą odpowiednich plików w .htaccess możemy tworzyć własne strony błędów. HTTP posiada numeryczne kody, które odpowiadają wynikom poszczególnych operacji jak i też błędów. Dzielą się one na następujące grupy:
1XX - kody informacyjne;
2XX - kody powodzenia;
3XX - kody przekierowania;
4XX - kody błędów aplikacji po stronie użytkownika;
5XX - kody błędów aplikacji po stronie serwera;
My zajmiemy się tymi dwoma ostatnimi, czyli komunikatami o błędach. Na początek musi wiedzieć dokładnie jakie kod co oznacza, a więc (źródło:http://czytelnia.reporter.pl/rozdzialy/aparec.pdf):
Wszystko co należy zrobić aby odwołać się do określonego błędu to dodać do pliku .htaccess następującą linię:
Oczywiście można pójść na łatwiznę i załatwić to bez tworzenia nowych stron o błędach w html tworząc zwykłe przekierowanie:
Kolejną możliwością jest zwyczajne wyświetlanie prostego tekstu, np.:
W skrócie to tyle na temat stron błędów w .htaccess. Reszta zależy już tylko od waszej wyobraźni. Dobrej zabawy!
1XX - kody informacyjne;
2XX - kody powodzenia;
3XX - kody przekierowania;
4XX - kody błędów aplikacji po stronie użytkownika;
5XX - kody błędów aplikacji po stronie serwera;
My zajmiemy się tymi dwoma ostatnimi, czyli komunikatami o błędach. Na początek musi wiedzieć dokładnie jakie kod co oznacza, a więc (źródło:http://czytelnia.reporter.pl/rozdzialy/aparec.pdf):
4xx — kody błędów klienta:
400 Złe zadanie
401 Dostęp nieautoryzowany
402 Wymagana opłata (niestosowane)
403 Dostęp zabroniony
404 Nieznaleziony
405 Metoda niedozwolona
406 Nie do zaakceptowania
407 Wymagane uwierzytelnienie proxy
408 Upłynął limit czasu zadania
409 Konflikt
410 Nieobecny
411 Potrzebna długość
412 Niespełnione warunki wstępne
413 Zadanie zbyt długie
414 Zadanie URI zbyt długie
415 Nieobsługiwany rodzaj medium
416 Zakres zadania niezadowalający
417 Oczekiwanie niespełnione
5xx — kody błędów serwera:
500 Wewnętrzny błąd serwera
501 Niezaimplementowany
502 Zła brama
503 Usługa niedostępna
504 Upłyną limit czasu bramy
505 Nieobsługiwana wersja protokołu HTTP
400 Złe zadanie
401 Dostęp nieautoryzowany
402 Wymagana opłata (niestosowane)
403 Dostęp zabroniony
404 Nieznaleziony
405 Metoda niedozwolona
406 Nie do zaakceptowania
407 Wymagane uwierzytelnienie proxy
408 Upłynął limit czasu zadania
409 Konflikt
410 Nieobecny
411 Potrzebna długość
412 Niespełnione warunki wstępne
413 Zadanie zbyt długie
414 Zadanie URI zbyt długie
415 Nieobsługiwany rodzaj medium
416 Zakres zadania niezadowalający
417 Oczekiwanie niespełnione
5xx — kody błędów serwera:
500 Wewnętrzny błąd serwera
501 Niezaimplementowany
502 Zła brama
503 Usługa niedostępna
504 Upłyną limit czasu bramy
505 Nieobsługiwana wersja protokołu HTTP
Wszystko co należy zrobić aby odwołać się do określonego błędu to dodać do pliku .htaccess następującą linię:
ErrorDocument 403 /errors/403.html
W katalogu /errors/ umieszczamy strony z opisami błędów, które zostają uruchomione w momencie wystąpienia danego błędu.Oczywiście można pójść na łatwiznę i załatwić to bez tworzenia nowych stron o błędach w html tworząc zwykłe przekierowanie:
ErrorDocument 404 http://www.google.pl/search?hl=pl&client=firefox-a&rls=org.mozilla%3Apl%3Aofficial&hs=pC6&q=space+of+code&btnG=Szukaj&lr=lang_pl
Kolejną możliwością jest zwyczajne wyświetlanie prostego tekstu, np.:
ErrorDocument 403 "Ten serwer wymaga uwierzytelnienia, musisz się zalogować"
W skrócie to tyle na temat stron błędów w .htaccess. Reszta zależy już tylko od waszej wyobraźni. Dobrej zabawy!
sobota, 9 sierpnia 2008
Tajniki pliku .htaccess - budowa od podstaw
Dzisiaj opowiem trochę o pliku który tak bardzo ułatwia mi wszelkie prace związane z Apache'm - mowa tu o .htaccess. Oczywiście sam plik jest zwykłym plikiem tekstowym w którym zapisujemy ustawienia serwera Apache dlatego należy uważać na wszelkie edytory tekstowe, które zapisują pliki z rozszerzeniem .txt bo wtedy zwyczajnie nasz plik nie będzie działał. A więc krótko; jeżeli chcesz zabezpieczyć pewne strony lub pliki na swoim serwerze przed niepowołanymi użytkownikami, zmienić wyświetlany w URL adres, zablokować niepożądanych gości po adresie IP, wyświetlać tylko niektóre pliki z katalogu, tworzyć przekierowania, zdefiniować jakie typy rozszerzeń będą otwierane przez jakie programy, wybrać czy plik ma być otwierany czy zapisywany na dysku i wiele wiele innych rzeczy to zdecydowanie powinieneś zapoznać się z plikiem .htaccess!
Ja zacznę od podstaw. Warto wiedzieć jak budować taki plik, więc zacznijmy od najbardziej praktycznej rzeczy jaki istnieje w programowaniu - od komentarzy. Komentarze w .htaccess tworzy się podobnie jak w PHP, czyli poprzez dodanie znaku # na początku linii. Warto również pamiętać aby każde linie zamykać enterem.
Do dzieła! Na początek zadbałbym o odpowiednie uprawnienia dostępu do pliku. Optymalnie będą to ustawienia 644, które pozwolą na dostęp do pliku przez serwer ale uniemożliwią jego zmianę z poziomu przeglądarki - wpisujemy w shellu
Pierwszym naszym wpisem będzie określenie domyślnego pliku strony WWW, do tego celu użyjemy
Teraz parę zdań na temat powiązań typów plików, czyli MimeType. Są to rozszerzenia, które zwracane są przeglądarce po znalezieniu na serwerze danego typu pliku. Chodzi tutaj o reakcję naszej przeglądarki na odczyt pliku z jakimś rozszerzeniem. Oczywiście większość rozszerzeń jest zdefiniowana domyślnie na naszym serwerze, czyli np. po kliknięciu w plik audio pojawia nam się monit odnośnie ściągnięcia pliku na dysk. Czasami jednak zdarza się, że chcemy aby konkretne rozszerzenia były otwierane trochę inaczej, np. jeśli chcemy niektóre pliki ściągać na dysk zamiast ich wyświetlać wpisujemy:
Możemy również wymusić otwieranie odpowiednich typów w plików w wybranych przez nasz programach - bardzo przydatne przy spakowanych plikach. Poniżej znajduję się listing przypisanie większości znanych formatów do aplikacji źródło: Internet Maker:
A teraz bardzo przydatna informacja dla osób, które mają problemy z kodowaniem tekstu na stronach. Dzięki odpowiednim wpisom w .htaccess możemy ustawić kodowanie dokumentów, np.:
Za pomocą pliku .htaccess można bardzo łatwo i szybko wprowadzić autoryzację użytkowników dla danego katalogu. Do tego celu będziemy musieli utworzyć plik .htpasswd w którym będą wpisywani użytkownicy oraz ich zakodowane hasła. Na stronie tools.dynamicdrive znajdziemy edytor pliku .htpasswd - wystarczy wypisać użytkowników oraz ich hasła, a skrypt wygeneruje nam odpowiedni kod do wklejenia do naszego pliku. Standardowo wpis w .htpasswd wygląda tak:<files html="dane_osobowe.html">
require valid-user
</files> Zabezpieczanie w ten sposób strony dotyczy tylko połączeń HTTP. Jeżeli ktoś połączy się z serwerem przez FTP to takie uwierzytelnienie nie będzie działać.
W kolejnym poście opiszę strony błędów, które możemy tworzyć za pomocą pliku .htaccess.
Ja zacznę od podstaw. Warto wiedzieć jak budować taki plik, więc zacznijmy od najbardziej praktycznej rzeczy jaki istnieje w programowaniu - od komentarzy. Komentarze w .htaccess tworzy się podobnie jak w PHP, czyli poprzez dodanie znaku # na początku linii. Warto również pamiętać aby każde linie zamykać enterem.
Do dzieła! Na początek zadbałbym o odpowiednie uprawnienia dostępu do pliku. Optymalnie będą to ustawienia 644, które pozwolą na dostęp do pliku przez serwer ale uniemożliwią jego zmianę z poziomu przeglądarki - wpisujemy w shellu
Chmod 644 .htaccess.Pierwszym naszym wpisem będzie określenie domyślnego pliku strony WWW, do tego celu użyjemy
DirectoryIndex. Tutaj możemy podać kilka nazw głównych plików, które oddzielamy spacjami np. DirectoryIndex index.php index.html index.htm glowna.php main.html. Tutaj ważna jest kolejność, jeżeli istnieje plik index.php to on będzie naszym domyślnym, jeżeli nie istnieje to następny w kolejności, czyli index.html. To jest bardzo przydatne w przypadku, gdy nasza strona ma trochę inną strukturę niż standardy, np. naszym startowym plikiem może być start.php, wtedy ten plik zostanie wczytany po wejściu na nasz serwer. Oczywiście jeżeli planujemy jakieś prace remontowe i nie chcemy żeby nasi goście oglądali ten bałagan dajemy DirectoryIndex roboty.html i wtedy nasi goście oglądają piękną informację na temat tego co się dzieje na stronie.Teraz parę zdań na temat powiązań typów plików, czyli MimeType. Są to rozszerzenia, które zwracane są przeglądarce po znalezieniu na serwerze danego typu pliku. Chodzi tutaj o reakcję naszej przeglądarki na odczyt pliku z jakimś rozszerzeniem. Oczywiście większość rozszerzeń jest zdefiniowana domyślnie na naszym serwerze, czyli np. po kliknięciu w plik audio pojawia nam się monit odnośnie ściągnięcia pliku na dysk. Czasami jednak zdarza się, że chcemy aby konkretne rozszerzenia były otwierane trochę inaczej, np. jeśli chcemy niektóre pliki ściągać na dysk zamiast ich wyświetlać wpisujemy:
AddType application/octet-stream .pdf .gz
Możemy również wymusić otwieranie odpowiednich typów w plików w wybranych przez nasz programach - bardzo przydatne przy spakowanych plikach. Poniżej znajduję się listing przypisanie większości znanych formatów do aplikacji źródło: Internet Maker:
1. #css, html, xml, asp, flash i inne
2. AddType text/css .css
3. AddType application/xhtml+xml .xhtml
4. AddType text/html .shtml
5. AddType text/xml .xml
6. AddType text/html .asp
7. Addtype application/x-httpd-php .php
8. AddType application/x-shockwave-flash .swf
9. AddType application/x-director .dir .dcr .dxr .fgd
10. AddType application/x-authorware-map .aam
11. AddType application/x-authorware-seg .aas
12. AddType application/x-authorware-bin .aab
13. AddType image/x-freehand .fh4 .fh5 .fh7 .fhc .fh
14. AddType application/x-java-applet .class
15. # dokumenty
16. AddType application/pdf .pdf
17. AddType application/msword .doc
18. #multimedia
19. AddType audio/mpeg .mp3
20. AddType video/x-msvideo .avi
21. AddType audio/x-wav .wav
22. AddType video/quicktime .mov .qt
23. AddType video/x-ms-asf .asf .asx
24. AddType audio/x-ms-wma .wma
25. AddType audio/x-ms-wax .wax
26. AddType video/x-ms-wmv .wmv
27. AddType video/x-ms-wvx .wvx
28. AddType video/x-ms-wm .wm
29. AddType video/x-ms-wmx .wmx
30. AddType application/x-ms-wmz .wmz
31. AddType application/x-ms-wmd .wmd
32. #skompresowane
33. AddType application/zip .zip
34. AddType application/x-gzip .gz
35. AddType application/x-gtar .gtar
36. AddType application/x-rar-compressed .rar
37. AddType application/octet-stream .dmg
38. AddType application/x-7z-compressed .7z
39. #graficzne
40. Addtype image/jpg .jpg
41. Addtype image/gif .gif
42. #pozostałe
43. AddType application/x-bittorrent .torrent
44. AddType application/vnd.rn-realmedia .rm
45. AddType audio/vnd.rn-realaudio .ra .ram
46. AddType video/vnd.rn-realvideo .rv
2. AddType text/css .css
3. AddType application/xhtml+xml .xhtml
4. AddType text/html .shtml
5. AddType text/xml .xml
6. AddType text/html .asp
7. Addtype application/x-httpd-php .php
8. AddType application/x-shockwave-flash .swf
9. AddType application/x-director .dir .dcr .dxr .fgd
10. AddType application/x-authorware-map .aam
11. AddType application/x-authorware-seg .aas
12. AddType application/x-authorware-bin .aab
13. AddType image/x-freehand .fh4 .fh5 .fh7 .fhc .fh
14. AddType application/x-java-applet .class
15. # dokumenty
16. AddType application/pdf .pdf
17. AddType application/msword .doc
18. #multimedia
19. AddType audio/mpeg .mp3
20. AddType video/x-msvideo .avi
21. AddType audio/x-wav .wav
22. AddType video/quicktime .mov .qt
23. AddType video/x-ms-asf .asf .asx
24. AddType audio/x-ms-wma .wma
25. AddType audio/x-ms-wax .wax
26. AddType video/x-ms-wmv .wmv
27. AddType video/x-ms-wvx .wvx
28. AddType video/x-ms-wm .wm
29. AddType video/x-ms-wmx .wmx
30. AddType application/x-ms-wmz .wmz
31. AddType application/x-ms-wmd .wmd
32. #skompresowane
33. AddType application/zip .zip
34. AddType application/x-gzip .gz
35. AddType application/x-gtar .gtar
36. AddType application/x-rar-compressed .rar
37. AddType application/octet-stream .dmg
38. AddType application/x-7z-compressed .7z
39. #graficzne
40. Addtype image/jpg .jpg
41. Addtype image/gif .gif
42. #pozostałe
43. AddType application/x-bittorrent .torrent
44. AddType application/vnd.rn-realmedia .rm
45. AddType audio/vnd.rn-realaudio .ra .ram
46. AddType video/vnd.rn-realvideo .rv
A teraz bardzo przydatna informacja dla osób, które mają problemy z kodowaniem tekstu na stronach. Dzięki odpowiednim wpisom w .htaccess możemy ustawić kodowanie dokumentów, np.:
AddDefaultCharset ISO-8859-1
AddDefaultCharset ISO-8859-2
AddDefaultCharset ISO-8859-2
Za pomocą pliku .htaccess można bardzo łatwo i szybko wprowadzić autoryzację użytkowników dla danego katalogu. Do tego celu będziemy musieli utworzyć plik .htpasswd w którym będą wpisywani użytkownicy oraz ich zakodowane hasła. Na stronie tools.dynamicdrive znajdziemy edytor pliku .htpasswd - wystarczy wypisać użytkowników oraz ich hasła, a skrypt wygeneruje nam odpowiedni kod do wklejenia do naszego pliku. Standardowo wpis w .htpasswd wygląda tak:
uzytkownik:/YKTtGojL9BVA
Skrypt ze strony dynamicdrive wygeneruje wam również kod do wklejenia do pliku .htaccess, który będzie miał postać:AuthName "Restricted Area"
AuthType Basic
AuthUserFile /home/mysite/.htpasswd
AuthGroupFile /dev/null
require valid-user
W polu restricted area możemy wpisać co chcemy, np. "Ta strefa wymaga autoryzacji, zaloguj się" - to właśnie wyświetli się podczas próby wejścia na zabezpieczony teren. AuthUserFile musi kierować do naszego pliku z hasłami, natomiast require valid-user odpowiada za obszar jaki ma być zabezpieczony hasłem. Jeżeli zostawimy tak jak jest to wtedy cała strona będzie wymagała zalogowania, natomiast jeżeli chcemy zabezpieczyć hasłem tylko jeden plik, np.:dane_osobowe.html to dodajemy odpowiednie tagi:AuthType Basic
AuthUserFile /home/mysite/.htpasswd
AuthGroupFile /dev/null
require valid-user
W kolejnym poście opiszę strony błędów, które możemy tworzyć za pomocą pliku .htaccess.
poniedziałek, 4 sierpnia 2008
Budujemy panel w PHP do zarządzania adresami sieci w Linux w oparciu o edycję pliku /etc/network/interfaces
Dzisiaj zajmiemy się budową panelu w PHP, który poprzez proste wpisywanie adresów w pola tekstowe będzie nam edytował plik /etc/network/interfaces po czym zrestartuje automatycznie sieć. Jest to bardzo przydatne jeżeli ktoś zarządza serwerem bądź ruterem na linuxie i zamiast łączyć się przez SSH po prostu loguje się na stronę jako admin lub ktokolwiek i tam swobodnie i bez przeszkód wpisuje swoje ustawienia sieci. Całość tłumacze w oparciu o Debiana.
Zaczynając pisać kod w PHP, który wykonuje pewne polecenia przez przez konsole należy zaznajomić się z prawami dostępu w linuxie. Jak wiadomo domyślnie wszelkie skrypty linuxa, które służą do edycji systemowych ustawień należą do właściciela i grupy root. Niestety (albo stety) nie możemy (nie chcemy) uruchomić serwera apachea jako root ponieważ jest to wysoce ryzykowne dla naszego serwera. W standardzie apache uruchamia wszelkie skrypty jako użytkownik www-data lub po prostu 33. Dlatego właśnie musimy zmienić właściciela oraz grupę wszystkich plików które będą przez nas używane na www-data.
Oto lista plików, których właścicieli musimy zmienić poleceniami:
1. /etc/network/interfaces
2. /etc/init.d/networking
3. /etc/network/run/ifstate
Ok, jeżeli mamy już zmienione uprawnienia możemy zabrać się za nasz panel, ale najpierw rzućmy okiem na nasz plik /etc/network/interfaces. U mnie wygląda on tak:
Tutaj każdy będzie musiał się wykazać inicjatywą i zbudować własny kod PHP pod swój plik interfaces.
Aby zbudować panel będziemy musieli utworzyć dla pliki PHP: panel.php i panel_edit.php.
Tak mniej więcej będzie wyglądał plik panel.php:
A tak będzie wyglądał nasz plik panel_edit.php:
Wszelkie szczegóły starałem się umieścić w kodzie w komentarzach. Kod nie jest skomplikowany, więc myślę że każdy sobie poradzi z jego zrozumieniem. W razie problemów proszę pisać w komentarzach - postaram się rozwiać wszelkie wątpliwości.
Zaczynając pisać kod w PHP, który wykonuje pewne polecenia przez przez konsole należy zaznajomić się z prawami dostępu w linuxie. Jak wiadomo domyślnie wszelkie skrypty linuxa, które służą do edycji systemowych ustawień należą do właściciela i grupy root. Niestety (albo stety) nie możemy (nie chcemy) uruchomić serwera apachea jako root ponieważ jest to wysoce ryzykowne dla naszego serwera. W standardzie apache uruchamia wszelkie skrypty jako użytkownik www-data lub po prostu 33. Dlatego właśnie musimy zmienić właściciela oraz grupę wszystkich plików które będą przez nas używane na www-data.
Oto lista plików, których właścicieli musimy zmienić poleceniami:
chown www-data [plik] oraz chgrp www-data [plik]:1. /etc/network/interfaces
2. /etc/init.d/networking
3. /etc/network/run/ifstate
Ok, jeżeli mamy już zmienione uprawnienia możemy zabrać się za nasz panel, ale najpierw rzućmy okiem na nasz plik /etc/network/interfaces. U mnie wygląda on tak:
auto lo
iface lo inet loopback
up ip l s imq0 up && ip l s imq1 up
auto eth0
iface eth0 inet static
address 212.244.101.111
netmask 255.255.255.53
network 10.5.1.0
broadcast 10.5.1.10
gateway 10.5.1.1
up echo 1 > /proc/sys/net/ipv4/conf/all/proxy_arp
auto eth1
iface eth1 inet static
address 212.244.101.129
netmask 255.255.255.128
network 212.244.101.128
broadcast 212.244.101.255
up route add -host 212.244.101.244 dev eth1
auto eth1:1
iface eth1:1 inet static
address 10.10.1.1
netmask 255.255.0.0
network 10.10.1.1
broadcast 10.10.1.255
auto eth1:0
iface eth1:0 inet static
address 172.16.171.1
netmask 255.255.255.0
network 172.16.171.0
broadcast 172.16.171.255
iface lo inet loopback
up ip l s imq0 up && ip l s imq1 up
auto eth0
iface eth0 inet static
address 212.244.101.111
netmask 255.255.255.53
network 10.5.1.0
broadcast 10.5.1.10
gateway 10.5.1.1
up echo 1 > /proc/sys/net/ipv4/conf/all/proxy_arp
auto eth1
iface eth1 inet static
address 212.244.101.129
netmask 255.255.255.128
network 212.244.101.128
broadcast 212.244.101.255
up route add -host 212.244.101.244 dev eth1
auto eth1:1
iface eth1:1 inet static
address 10.10.1.1
netmask 255.255.0.0
network 10.10.1.1
broadcast 10.10.1.255
auto eth1:0
iface eth1:0 inet static
address 172.16.171.1
netmask 255.255.255.0
network 172.16.171.0
broadcast 172.16.171.255
Tutaj każdy będzie musiał się wykazać inicjatywą i zbudować własny kod PHP pod swój plik interfaces.
Aby zbudować panel będziemy musieli utworzyć dla pliki PHP: panel.php i panel_edit.php.
Tak mniej więcej będzie wyglądał plik panel.php:
A tak będzie wyglądał nasz plik panel_edit.php:
Wszelkie szczegóły starałem się umieścić w kodzie w komentarzach. Kod nie jest skomplikowany, więc myślę że każdy sobie poradzi z jego zrozumieniem. W razie problemów proszę pisać w komentarzach - postaram się rozwiać wszelkie wątpliwości.
piątek, 25 lipca 2008
Jak wyświetlić czytelny i kolorowy kod na Blogspot?
Jeżeli chcemy na naszym blogu wyświetlać sformatowany (highlighted) kod jakiegokolwiek języka musimy zrobić kilka następujących czynności:
1. Instalujemy program o nazwie jEdit. Najlepiej najnowszą wersję. Jeśli ściągniemy Java based installer żadne skróty nie dodadzą nam się w systemie. Wtedy uruchamiamy program wchodząc do katalogu docelowego i odpalamy plik jedit.jar.
2. Uruchamiamy program, wchodzimy do zakładki Plugins -> Plugin Manager. Następnie klikamy Download options i wybieramy serwer lustrzany, który jest nam najbliższy. Teraz możemy zrestartować jEdit.
3. Ponownie wchodzimy do Plugin Manager i klikamy zakładkę Install. Odnajdujemy plugin o nazwie Code2HTML, zaznaczamy go i instalujemy.
4. Teraz musimy sobie przygotować kod, który będziemy chcieli wyświetlić i zapisać go na dysku. Musimy dopilnować aby plik miał prawidłowe rozszerzenie - jEdit potrafi rozpoznawać różne języki i dostosowuje do nich konkretne formatowania kodu. Kiedy wczytamy już tak przygotowany plik do programu, wchodzimy do Plugins -> Code2HTML -> HTMLize current buffer.
5. Edytujemy dowolnie wynik konwersji - możemy tu pozmieniać kolory oraz formatowania dla poszczególnych sesji. Zapisujemy gotowy plik z rozszerzeniem .html i uploadujemy go na jakiś serwer. Ja używam do tego google pages. Bardzo wygodne.
6. Teraz pisząc nowego posta na blogspot po prostu wstawiamy taki kod:Można tutaj przy okazji pogrzebać trochę w css'ie aby dopasować wygląd tego okna do swojego bloga. Poniżej znajduje się przykładowa funkcja służąca do formatowania kodu w PHP przygotowana w jEdit:
OK, to tyle na temat kolorowania składni kodu. Jeżeli ktoś zna jakieś inne ciekawe sposoby na wygenerowanie kodu na stronie w bardziej przejrzysty sposób to proszę pisać w komentarzach lub na maila.
1. Instalujemy program o nazwie jEdit. Najlepiej najnowszą wersję. Jeśli ściągniemy Java based installer żadne skróty nie dodadzą nam się w systemie. Wtedy uruchamiamy program wchodząc do katalogu docelowego i odpalamy plik jedit.jar.
2. Uruchamiamy program, wchodzimy do zakładki Plugins -> Plugin Manager. Następnie klikamy Download options i wybieramy serwer lustrzany, który jest nam najbliższy. Teraz możemy zrestartować jEdit.
3. Ponownie wchodzimy do Plugin Manager i klikamy zakładkę Install. Odnajdujemy plugin o nazwie Code2HTML, zaznaczamy go i instalujemy.
4. Teraz musimy sobie przygotować kod, który będziemy chcieli wyświetlić i zapisać go na dysku. Musimy dopilnować aby plik miał prawidłowe rozszerzenie - jEdit potrafi rozpoznawać różne języki i dostosowuje do nich konkretne formatowania kodu. Kiedy wczytamy już tak przygotowany plik do programu, wchodzimy do Plugins -> Code2HTML -> HTMLize current buffer.
5. Edytujemy dowolnie wynik konwersji - możemy tu pozmieniać kolory oraz formatowania dla poszczególnych sesji. Zapisujemy gotowy plik z rozszerzeniem .html i uploadujemy go na jakiś serwer. Ja używam do tego google pages. Bardzo wygodne.
6. Teraz pisząc nowego posta na blogspot po prostu wstawiamy taki kod:Można tutaj przy okazji pogrzebać trochę w css'ie aby dopasować wygląd tego okna do swojego bloga. Poniżej znajduje się przykładowa funkcja służąca do formatowania kodu w PHP przygotowana w jEdit:
OK, to tyle na temat kolorowania składni kodu. Jeżeli ktoś zna jakieś inne ciekawe sposoby na wygenerowanie kodu na stronie w bardziej przejrzysty sposób to proszę pisać w komentarzach lub na maila.
Jak wyświetlić kolorowy (highlighted) kod PHP na swojej stronie?
Czasami zdarza się, że potrzebujemy czytelnie wyświetlić jakiś kod PHP na własnej stronie. Moglibyśmy go formatować za pomocą kodu HTML, CSS lub ewentualnie napisać jakąś funkcję w PHP, która zrobi to za nas. Niestety wszystkie te rozwiązania są bardzo czasochłonne. Tutaj przychodzi nam z pomocą funkcja highlight_string(). Za jej pomocą możemy bardzo łatwo wyświetlić kod PHP, który umieszczony w () zostanie odpowiednio sformatowany. A więc wpisując:
Zobaczysz mniej więcej coś takiego:
Napisałem "mniej więcej" ponieważ na blogspot nie ma możliwości dodawania skryptów PHP. Tak naprawdę kolorowy kod na blogspot uzyskuje się całkiem inaczej. Niedługo opiszę ten sposób.
Aby dowiedzieć się więcej szczegółów na temat highlight_string() zapraszam na stronę manuala PHP.
Zobaczysz mniej więcej coś takiego:
Napisałem "mniej więcej" ponieważ na blogspot nie ma możliwości dodawania skryptów PHP. Tak naprawdę kolorowy kod na blogspot uzyskuje się całkiem inaczej. Niedługo opiszę ten sposób.
Aby dowiedzieć się więcej szczegółów na temat highlight_string() zapraszam na stronę manuala PHP.
niedziela, 6 lipca 2008
Postfix - podstawowa konfiguracja serwera poczty na Linuxie
No więc stało się. W ostanim poście pisałem na temat konfiguracji DenyHosta i okazało się, że bardzo dobrą sprawą byłoby gdybyśmy mieli skonfigurowany na naszym systmie serwer poczty. Wydaję mi się, że najlepszą alternatywą do zasłużonego i niezbyt bezpieczniego sendmaila jest postfix. Nie będe tu się rozpisywał na temat szczegółowej konfiguracji, jeżeli ktoś będzie chciał szczegołowo wejść w temat to na pewno znajdzie mnóstwo dokumentacji w internecie, polecam przejrzeć tą na stronie postfixa dokumentacja. Teraz po protsu zróbmy tak żeby postfix działał optymalnie konfigurując go pod "przeciętnego" użytkownika. Zaczynajmy!
1. Ten punkt jest opcjonalny - dla tych którzy mają zainstalowany starszy serwer poczty jakim jest sendmail. Przede wszystkim musimy go usunąć. Najpeirw sprawdzamy czy sendmail jest obecnie uruchomiony:
Jeżeli tak, to go wyłączamy:
i usuwamy:
Jeżeli usunięcie w ten sposób jest niemożliwe należy usunąc sendmaila ręcznie. Robimy to następująco:
po czym zmieniamy nazwy wyświetlonych plików:
Teraz zabieramy prawa temu plikowi:
Następnie usuwamy go ze skryptów startowych. Zależnie od dystrybucji, wpis powinien znajdować się w /etc/rc.d/ lub w /etc/rc.d/init.d . Należy odnaleźć wywołanie sendmaila w którymś z plików rc.X o je usunąć lub zahashować (#). W jego miejsce wpisujesmy
2. Przechodzimy do instalacji postfixa - najłatwiejszy sposób to:
po czym uruchomi nam się podstawowa konfiguracja. W pierwszym oknie klikamy OK, następnie w General type of configuration wybieramy Internet Site. W następnym oknie zobaczymy Mail Name defaultowo przypisana jest tu nazwa hosta, więc tak możemy zostawić. Teraz możemy przejść do właściwej części konfiguracji.
3. Zabieramy się za konfigurację lokalną. Wszystkie pliki konfiguracyjne znajdują się w /etc/postfix/. Nie ma tego dużo - my skupimy się na pliku main.cf. Przydatne nam będzie polecenie, które wyświetla wszystkie ustawienia oraz zmienne postfixa - postconf. Sprobuj je wywołać samo, a następnie z parametrem np. myhostname.
Otwieramy plik konfiguracyjny postfixa:
Odnajdujemy wpis myhostname i upewniamy się, że jest tam wpisana nazwa naszego hosta.
Dla ułatwienia wrzucę tutaj podstawowy plik konfiguracyjny, który powinien działać:
1. Ten punkt jest opcjonalny - dla tych którzy mają zainstalowany starszy serwer poczty jakim jest sendmail. Przede wszystkim musimy go usunąć. Najpeirw sprawdzamy czy sendmail jest obecnie uruchomiony:
ps xJeżeli tak, to go wyłączamy:
/etc/init.d/sendmail stopi usuwamy:
apt-get remove --purge sendmailJeżeli usunięcie w ten sposób jest niemożliwe należy usunąc sendmaila ręcznie. Robimy to następująco:
which sendmailpo czym zmieniamy nazwy wyświetlonych plików:
mv sendmail sendmail.OFFTeraz zabieramy prawa temu plikowi:
chmod 700 sendmail.OFFNastępnie usuwamy go ze skryptów startowych. Zależnie od dystrybucji, wpis powinien znajdować się w /etc/rc.d/ lub w /etc/rc.d/init.d . Należy odnaleźć wywołanie sendmaila w którymś z plików rc.X o je usunąć lub zahashować (#). W jego miejsce wpisujesmy
postfix start.2. Przechodzimy do instalacji postfixa - najłatwiejszy sposób to:
apt-get install postfix po czym uruchomi nam się podstawowa konfiguracja. W pierwszym oknie klikamy OK, następnie w General type of configuration wybieramy Internet Site. W następnym oknie zobaczymy Mail Name defaultowo przypisana jest tu nazwa hosta, więc tak możemy zostawić. Teraz możemy przejść do właściwej części konfiguracji.
3. Zabieramy się za konfigurację lokalną. Wszystkie pliki konfiguracyjne znajdują się w /etc/postfix/. Nie ma tego dużo - my skupimy się na pliku main.cf. Przydatne nam będzie polecenie, które wyświetla wszystkie ustawienia oraz zmienne postfixa - postconf. Sprobuj je wywołać samo, a następnie z parametrem np. myhostname.
Otwieramy plik konfiguracyjny postfixa:
nano /etc/postfix/main.cfOdnajdujemy wpis myhostname i upewniamy się, że jest tam wpisana nazwa naszego hosta.
Dla ułatwienia wrzucę tutaj podstawowy plik konfiguracyjny, który powinien działać:
command_directory = /usr/sbin
mail_owner = postfix
mydomain = wpisujemy nazwę naszej domeny
myhostname = wpisujemy nazwę naszego hosta
myorigin = $mydomain
mydestination = $myhostname, localhost.$mydomain, mail.$mydomain, localhost, $mydomain
relayhost =
relay_domains = $mydestination
mynetworks = 127.0.0.0/8 192.168.1.1/24 Dzięki pierwszemu adresowi nasza poczta rozsyłana jest globalnie, drugi adres jest adresem naszej podsieci - przeważnie jest to także nasza brama, dzięki temu adresowi maile są wysyłane w Świat.
inet_interfaces = all
inet_protocols = ipv4
4. Zapisujemy plik, wpisujemy postfix reload i teraz już możemy wysyłać pocztę za pomocą polecenia mail.
Podstawową konfigurację mamy za sobą. Tak skonfigurowany serwer poczty nie jest chroniony w żaden sposób i może posłużyć za bramę dla spamerów. Jeżeli naszym dostawcą internetu TP S.A. to nasze maile będą odbijane przez gmail. Na nasze maile również nie można w żaden sposób odpowiedzieć czy napisać do nas z zewnątrz. Wszystkie te problemy rozwiąże w kolejnych postach.
czwartek, 3 lipca 2008
DenyHosts, czyli jeszcze bezpieczniejsze SSH
Witam po długiej przerwie. Kto by pomyślał, że to będzie taki pracowity okres… Przejdźmy do rzeczy: ostatnimi czasy poświęcam więcej czasu systemowi o wiele znaczącej nazwie jaką jest Linux. Moje ostatnie plany „zmusiły” mnie do postawienia serwera na Debianie i jak się okazało sprawiło mi to wiele frajdy. Wszystko wspaniale działa – mysql, PHP, samba i rzecz, która była mi niezbędna do pracy – SSH. Po pewnym czasie zauważyłem, że na moim serwerze generuje się dziwny ruch – możemy to zobaczyć wpisując jako root następującą komendę:
Wynik będzie prawdopodobnie podobny do tego poniżej tylko, że znacznie duższy.
Interesujące, prawda? Są to boty, które przeszukują sieć w poszukiwaniu dziur w zabezpieczeniach. Jeżeli im się uda – mamy kolejne zoombie w necie. Proszę zauważyć, że w tym przypadku wszystkie próby pochodzą z jednego adresu. Można to zrobić ręcznie i po prostu zablokować takie ip na firewallu ale to działa tylko na chwilę, takich adresów jest naprawdę wiele, przynajmniej kilka dziennie, więc to by była syzyfowa praca. Tutaj z pomocą przychodzi nam program o nazwie DenyHosts pobierz.
To jest bardzo prosty program ale jego funkcjonalność wydaję się nieoceniona – blokuje wszystkie takie ataki wg ustawionych kryteriów, powiadamia nas o tym na maila oraz wysyła adres agresora na swój serwer i tam uaktualnia ogólną bazę danych zbanowanych adresów, które każdy klient blokuje również u siebie. Obecnie z DenyHosts korzysta 6800 klientów, więc została utworzona już całkiem pokaźna baza. Przy uaktualnianiu cogodzinnym do naszej listy banów dodaje się kilkadziesiąt nowych adresów. Po poprawnej konfiguracji takie ataki stają się naprawdę sporadyczne.
A teraz do rzeczy – jak to się robi?
1. A więc zaczynamy standardowo, czyli od instalacji programu:
2. Program jest już defaultowo skonfigurowany i uruchamia się już po instalacji ale my chcemy trochę usprawnić jego pracę. Edytujemy plik konfiguracyjny:
3. Zabieramy się do edycji. Pierwsze sekcje pomijamy bo nas za bardzo nie interesują, dotyczą rozmieszczenia plików z logami itp. Kolejna sekcja wygląda następująco:
Tutaj ustawiamy po jakim czasie adres ma być usuwany z naszej listy zbanowanych adresów. Defaultowo j PURGE_DENY jest bez parametrów co oznacza, że adresy nie będą w ogóle usuwany - tak zostawiamy.
Tutaj ustawiamy dla których usług ma być blokowany dany adres. Standardowo jest ustawione blokowanie na wszsytkie usługi - tutaj również tak zostawiamy.
W tym miejscu ustawiamy po ilu nieudanych próbach adres będzie blokowany dla kont których nie ma w /etc/passwd . Przeważnie dotyczy to ataków słowników. Sądze, że my znamy własny login, więc można to spokojnie zmniejszyć do 2 prób.
Ta reguła dotyczy prób logowania na istniejące konta. Radzę zachować tutaj ostrożność - my też możemy się pomylić lub zapomnieć hasła. 7-8 prób będzie to optymalną wartością.
Powyższa opcja od razu blokuje próbę logowania jako root.
Ta opcja blokuje wszystkie próby użycia loginu, który jest wymieniony w pliku restricted-usernames.
Tutaj powinniśmy mieć YES. Program monitoruje wtedy raporty DenyHosts w celu odnalazienia podejrzanych logowań lub odnajduje wpisy, które nie są przydatne.
Jeżeli YES to atakujący host będzie informowany o blokowaniu (o ile to jest możliwe). Jeżeli zależy nam na prędkości proponuje to wyłączyć.
Zabezpieczenie przed urchomieniem dwa razy programu. Usuwamy komentarz przy naszej dystrybucji.
W tym miejscu możemy sobie ustawić powiadomienia na adres e-mail. Wszystkie ruchy w logach będą raportowane. Polecam jeżeli ktoś ma skonfigurowany serwer poczty, polecam Postfix. Może w kolejnym poście opiszę konfigurację takiego serwera.
Tutaj kolejne ustawienia poczty - ustawiamy nadawacę, temat i format daty.
Kolejne sekcje zostawiamy defaultowo aż do:
Tutaj wybieramy czy DenyHosts ma się łączyć z serwerem w celu aktualizacji bazy adresów. Defaultowo wyłączone - proponuję włączyć poprzez usunięcie hasha przy SYNC_SERVER.
Wybieramy jak często ma być robiona aktualizacja. Ja mam 1h ale jeżeli nie lubimy jak nasz serwer często się aktualizuje możemy tu ustawić np. 12h.
Tutaj wybieramy czy chcemy robić upload naszej bazy zablopkowanych adresów. Proponuje YES.
Czy chcemy ściągać bazy adresów innych użytkowników? Oczywiście, że tak.
Tutaj mała opcja filtrowania. Jeżeli ustawimy na 1 to wtedy wszystkie adresy zablokowane przez przynajmniej jeden serwer zostaną również zablokowane u nas. Proponuje zostawić jak jest.
4. Zapisujemy plik i wpisujemy:
i możemy spać spokojnie ;) Od tej pory każdy kto będzie próbował się zalogować w podejrzany sposób będzie blokowany a jego ip będzie umieszczane w /etc/hosts.deny . Wszystkie logi programu, łącznie z zablokowanymi adresami znajdują się w /var/log/denyhosts.
Dziękuje i pozdrawiam!
cat /var/log/auth.log |grep invalidWynik będzie prawdopodobnie podobny do tego poniżej tylko, że znacznie duższy.
Jul 3 20:59:49 debian-serwer sshd[9627]: Failed password for invalid user alex from 193.218.155.219 port 36407 ssh2
Jul 3 20:59:52 debian-serwer sshd[9629]: Failed password for invalid user brett from 193.218.155.219 port 36504 ssh2
Jul 3 20:59:54 debian-serwer sshd[9631]: Failed password for invalid user mike from 193.218.155.219 port 37059 ssh2
Jul 3 20:59:57 debian-serwer sshd[9633]: Failed password for invalid user alan from 193.218.155.219 port 37120 ssh2
Jul 3 20:59:59 debian-serwer sshd[9635]: Failed password for invalid user data from 193.218.155.219 port 37707 ssh2
Jul 3 21:00:04 debian-serwer sshd[9639]: Failed password for invalid user http from 193.218.155.219 port 37879 ssh2
Jul 3 21:00:06 debian-serwer sshd[9641]: Failed password for invalid user httpd from 193.218.155.219 port 39878 ssh2
Jul 3 21:00:16 debian-serwer sshd[9649]: Failed password for invalid user info from 193.218.155.219 port 43904 ssh2
Jul 3 21:00:18 debian-serwer sshd[9651]: Failed password for invalid user shop from 193.218.155.219 port 44402 ssh2
Jul 3 21:00:21 debian-serwer sshd[9653]: Failed password for invalid user sales from 193.218.155.219 port 45696 ssh2
Jul 3 21:00:23 debian-serwer sshd[9655]: Failed password for invalid user web from 193.218.155.219 port 46620 ssh2
Jul 3 21:00:26 debian-serwer sshd[9657]: Failed password for invalid user www from 193.218.155.219 port 47784 ssh2
Jul 3 21:00:28 debian-serwer sshd[9659]: Failed password for invalid user wwwrun from 193.218.155.219 port 48591 ssh2
Jul 3 21:00:31 debian-serwer sshd[9661]: Failed password for invalid user adam from 193.218.155.219 port 49459 ssh2
Jul 3 21:00:33 debian-serwer sshd[9663]: Failed password for invalid user stephen from 193.218.155.219 port 50373 ssh2
Jul 3 21:00:35 debian-serwer sshd[9665]: Failed password for invalid user richard from 193.218.155.219 port 51208 ssh2
Jul 3 21:00:38 debian-serwer sshd[9667]: Failed password for invalid user george from 193.218.155.219 port 51476 ssh2
Jul 3 21:00:40 debian-serwer sshd[9669]: Failed password for invalid user michael from 193.218.155.219 port 52192 ssh2
Jul 3 21:00:43 debian-serwer sshd[9671]: Failed password for invalid user john from 193.218.155.219 port 52903 ssh2
Jul 3 21:00:46 debian-serwer sshd[9673]: Failed password for invalid user david from 193.218.155.219 port 53839 ssh2
Jul 3 21:00:48 debian-serwer sshd[9675]: Failed password for invalid user paul from 193.218.155.219 port 54252 ssh2
Jul 3 21:00:53 debian-serwer sshd[9679]: Failed password for invalid user angel from 193.218.155.219 port 55321 ssh2
Jul 3 21:00:58 debian-serwer sshd[9683]: Failed password for invalid user pgsql from 193.218.155.219 port 56702 ssh2
Jul 3 21:01:01 debian-serwer sshd[9685]: Failed password for invalid user pgsql from 193.218.155.219 port 57653 ssh2
Jul 3 21:01:06 debian-serwer sshd[9689]: Failed password for invalid user adm from 193.218.155.219 port 58824 ssh2
Jul 3 21:01:09 debian-serwer sshd[9691]: Failed password for invalid user ident from 193.218.155.219 port 59109 ssh2
Jul 3 21:01:11 debian-serwer sshd[9693]: Failed password for invalid user resin from 193.218.155.219 port 60094 ssh2Interesujące, prawda? Są to boty, które przeszukują sieć w poszukiwaniu dziur w zabezpieczeniach. Jeżeli im się uda – mamy kolejne zoombie w necie. Proszę zauważyć, że w tym przypadku wszystkie próby pochodzą z jednego adresu. Można to zrobić ręcznie i po prostu zablokować takie ip na firewallu ale to działa tylko na chwilę, takich adresów jest naprawdę wiele, przynajmniej kilka dziennie, więc to by była syzyfowa praca. Tutaj z pomocą przychodzi nam program o nazwie DenyHosts pobierz.
To jest bardzo prosty program ale jego funkcjonalność wydaję się nieoceniona – blokuje wszystkie takie ataki wg ustawionych kryteriów, powiadamia nas o tym na maila oraz wysyła adres agresora na swój serwer i tam uaktualnia ogólną bazę danych zbanowanych adresów, które każdy klient blokuje również u siebie. Obecnie z DenyHosts korzysta 6800 klientów, więc została utworzona już całkiem pokaźna baza. Przy uaktualnianiu cogodzinnym do naszej listy banów dodaje się kilkadziesiąt nowych adresów. Po poprawnej konfiguracji takie ataki stają się naprawdę sporadyczne.
A teraz do rzeczy – jak to się robi?
1. A więc zaczynamy standardowo, czyli od instalacji programu:
sudo apt-get install denyhosts2. Program jest już defaultowo skonfigurowany i uruchamia się już po instalacji ale my chcemy trochę usprawnić jego pracę. Edytujemy plik konfiguracyjny:
sudo nano /etc/denyhosts.conf3. Zabieramy się do edycji. Pierwsze sekcje pomijamy bo nas za bardzo nie interesują, dotyczą rozmieszczenia plików z logami itp. Kolejna sekcja wygląda następująco:
########################################################################
#
# PURGE_DENY: removed HOSTS_DENY entries that are older than this time
# when DenyHosts is invoked with the --purge flag
#
# format is: i[dhwmy]
# Where 'i' is an integer (eg. 7)
# 'm' = minutes
# 'h' = hours
# 'd' = days
# 'w' = weeks
# 'y' = years
#
# never purge:
PURGE_DENY =
#
# purge entries older than 1 week
#PURGE_DENY = 1w
#
# purge entries older than 5 days
#PURGE_DENY = 5d
#######################################################################
Tutaj ustawiamy po jakim czasie adres ma być usuwany z naszej listy zbanowanych adresów. Defaultowo j PURGE_DENY jest bez parametrów co oznacza, że adresy nie będą w ogóle usuwany - tak zostawiamy.
#######################################################################
#
# BLOCK_SERVICE: the service name that should be blocked in HOSTS_DENY
#
# man 5 hosts_access for details
#
# eg. sshd: 127.0.0.1 # will block sshd logins from 127.0.0.1
#
# To block all services for the offending host:
#BLOCK_SERVICE = ALL
# To block only sshd:
BLOCK_SERVICE = sshd
# To only record the offending host and nothing else (if using
# an auxilary file to list the hosts). Refer to:
# http://denyhosts.sourceforge.net/faq.html#aux
#BLOCK_SERVICE =
#
#######################################################################
Tutaj ustawiamy dla których usług ma być blokowany dany adres. Standardowo jest ustawione blokowanie na wszsytkie usługi - tutaj również tak zostawiamy.
#######################################################################
#
# DENY_THRESHOLD_INVALID: block each host after the number of failed login
# attempts has exceeded this value. This value applies to invalid
# user login attempts (eg. non-existent user accounts)
#
DENY_THRESHOLD_INVALID = 5
#
#######################################################################
W tym miejscu ustawiamy po ilu nieudanych próbach adres będzie blokowany dla kont których nie ma w /etc/passwd . Przeważnie dotyczy to ataków słowników. Sądze, że my znamy własny login, więc można to spokojnie zmniejszyć do 2 prób.
#######################################################################
#
# DENY_THRESHOLD_VALID: block each host after the number of failed
# login attempts has exceeded this value. This value applies to valid
# user login attempts (eg. user accounts that exist in /etc/passwd) except
# for the "root" user
#
DENY_THRESHOLD_VALID = 10
#
#######################################################################
Ta reguła dotyczy prób logowania na istniejące konta. Radzę zachować tutaj ostrożność - my też możemy się pomylić lub zapomnieć hasła. 7-8 prób będzie to optymalną wartością.
#######################################################################
#
# DENY_THRESHOLD_ROOT: block each host after the number of failed
# login attempts has exceeded this value. This value applies to
# "root" user login attempts only.
#
DENY_THRESHOLD_ROOT = 1
#
#######################################################################
Powyższa opcja od razu blokuje próbę logowania jako root.
#######################################################################
#
# DENY_THRESHOLD_RESTRICTED: block each host after the number of failed
# login attempts has exceeded this value. This value applies to
# usernames that appear in the WORK_DIR/restricted-usernames file only.
#
DENY_THRESHOLD_RESTRICTED = 1
#
#######################################################################
Ta opcja blokuje wszystkie próby użycia loginu, który jest wymieniony w pliku restricted-usernames.
#######################################################################
#
# SUSPICIOUS_LOGIN_REPORT_ALLOWED_HOSTS
#
# SUSPICIOUS_LOGIN_REPORT_ALLOWED_HOSTS=YES|NO
# If set to YES, if a suspicious login attempt results from an allowed-host
# then it is considered suspicious. If this is NO, then suspicious logins
# from allowed-hosts will not be reported. All suspicious logins from
# ip addresses that are not in allowed-hosts will always be reported.
#
SUSPICIOUS_LOGIN_REPORT_ALLOWED_HOSTS=YES
######################################################################
Tutaj powinniśmy mieć YES. Program monitoruje wtedy raporty DenyHosts w celu odnalazienia podejrzanych logowań lub odnajduje wpisy, które nie są przydatne.
######################################################################
#
# HOSTNAME_LOOKUP
#
# HOSTNAME_LOOKUP=YES|NO
# If set to YES, for each IP address that is reported by Denyhosts,
# the corresponding hostname will be looked up and reported as well
# (if available).
#
HOSTNAME_LOOKUP=YES
#
######################################################################
Jeżeli YES to atakujący host będzie informowany o blokowaniu (o ile to jest możliwe). Jeżeli zależy nam na prędkości proponuje to wyłączyć.
######################################################################
#
# LOCK_FILE
#
# LOCK_FILE=/path/denyhosts
# If this file exists when DenyHosts is run, then DenyHosts will exit
# immediately. Otherwise, this file will be created upon invocation
# and deleted upon exit. This ensures that only one instance is
# running at a time.
#
# Redhat/Fedora:
#LOCK_FILE = /var/lock/subsys/denyhosts
#
# Debian
LOCK_FILE = /var/run/denyhosts.pid
#
# Misc
#LOCK_FILE = /tmp/denyhosts.lock
#
######################################################################
Zabezpieczenie przed urchomieniem dwa razy programu. Usuwamy komentarz przy naszej dystrybucji.
#######################################################################
#
# ADMIN_EMAIL: if you would like to receive emails regarding newly
# restricted hosts and suspicious logins, set this address to
# match your email address. If you do not want to receive these reports
# leave this field blank (or run with the --noemail option)
#
# Multiple email addresses can be delimited by a comma, eg:
# ADMIN_EMAIL = foo@bar.com, bar@foo.com, etc@foobar.com
#
ADMIN_EMAIL = xxx@xxx.pl
#
#######################################################################
#######################################################################
#
# SMTP_HOST and SMTP_PORT: if DenyHosts is configured to email
# reports (see ADMIN_EMAIL) then these settings specify the
# email server address (SMTP_HOST) and the server port (SMTP_PORT)
#
#
SMTP_HOST = localhost
SMTP_PORT = 25
#
#######################################################################
#######################################################################
#
# SMTP_USERNAME and SMTP_PASSWORD: set these parameters if your
# smtp email server requires authentication
#
#SMTP_USERNAME=foo
#SMTP_PASSWORD=bar
#
#####################################################################
W tym miejscu możemy sobie ustawić powiadomienia na adres e-mail. Wszystkie ruchy w logach będą raportowane. Polecam jeżeli ktoś ma skonfigurowany serwer poczty, polecam Postfix. Może w kolejnym poście opiszę konfigurację takiego serwera.
#######################################################################
#
# SMTP_FROM: you can specify the "From:" address in messages sent
# from DenyHosts when it reports thwarted abuse attempts
#
SMTP_FROM = DenyHosts
#
#######################################################################
#######################################################################
#
# SMTP_SUBJECT: you can specify the "Subject:" of messages sent
# by DenyHosts when it reports thwarted abuse attempts
SMTP_SUBJECT = DenyHosts Report
#
######################################################################
######################################################################
#
# SMTP_DATE_FORMAT: specifies the format used for the "Date:" header
# when sending email messages.
#
# for possible values for this parameter refer to: man strftime
#
# the default:
#
#SMTP_DATE_FORMAT = %a, %d %b %Y %H:%M:%S %z
#
######################################################################
Tutaj kolejne ustawienia poczty - ustawiamy nadawacę, temat i format daty.
Kolejne sekcje zostawiamy defaultowo aż do:
#######################################################################
#
# SYNC_SERVER: The central server that communicates with DenyHost
# daemons. Currently, denyhosts.net is the only available server
# however, in the future, it may be possible for organizations to
# install their own server for internal network synchronization
#
# To disable synchronization (the default), do nothing.
#
# To enable synchronization, you must uncomment the following line:
#SYNC_SERVER = http://xmlrpc.denyhosts.net:9911
#
#######################################################################
Tutaj wybieramy czy DenyHosts ma się łączyć z serwerem w celu aktualizacji bazy adresów. Defaultowo wyłączone - proponuję włączyć poprzez usunięcie hasha przy SYNC_SERVER.
#######################################################################
#
# SYNC_INTERVAL: the interval of time to perform synchronizations if
# SYNC_SERVER has been uncommented. The default is 1 hour.
#
#SYNC_INTERVAL = 1h
#
#######################################################################
Wybieramy jak często ma być robiona aktualizacja. Ja mam 1h ale jeżeli nie lubimy jak nasz serwer często się aktualizuje możemy tu ustawić np. 12h.
#######################################################################
#
# SYNC_UPLOAD: allow your DenyHosts daemon to transmit hosts that have
# been denied? This option only applies if SYNC_SERVER has
# been uncommented.
# The default is SYNC_UPLOAD = yes
#
#SYNC_UPLOAD = no
SYNC_UPLOAD = yes
#
#######################################################################
Tutaj wybieramy czy chcemy robić upload naszej bazy zablopkowanych adresów. Proponuje YES.
#######################################################################
#
# SYNC_DOWNLOAD: allow your DenyHosts daemon to receive hosts that have
# been denied by others? This option only applies if SYNC_SERVER has
# been uncommented.
# The default is SYNC_DOWNLOAD = yes
#
#SYNC_DOWNLOAD = no
#SYNC_DOWNLOAD = yes
#
#
#
#######################################################################
Czy chcemy ściągać bazy adresów innych użytkowników? Oczywiście, że tak.
#######################################################################
#
# SYNC_DOWNLOAD_THRESHOLD: If SYNC_DOWNLOAD is enabled this parameter
# filters the returned hosts to those that have been blocked this many
# times by others. That is, if set to 1, then if a single DenyHosts
# server has denied an ip address then you will receive the denied host.
#
# See also SYNC_DOWNLOAD_RESILIENCY
#
#SYNC_DOWNLOAD_THRESHOLD = 10
#
# The default is SYNC_DOWNLOAD_THRESHOLD = 3
#
#SYNC_DOWNLOAD_THRESHOLD = 3
#
#######################################################################
Tutaj mała opcja filtrowania. Jeżeli ustawimy na 1 to wtedy wszystkie adresy zablokowane przez przynajmniej jeden serwer zostaną również zablokowane u nas. Proponuje zostawić jak jest.
4. Zapisujemy plik i wpisujemy:
sudo /etc/init.d/denyhosts restarti możemy spać spokojnie ;) Od tej pory każdy kto będzie próbował się zalogować w podejrzany sposób będzie blokowany a jego ip będzie umieszczane w /etc/hosts.deny . Wszystkie logi programu, łącznie z zablokowanymi adresami znajdują się w /var/log/denyhosts.
Dziękuje i pozdrawiam!
Subskrybuj:
Posty (Atom)


